
כדי להבין היטב את אופן הפעולה של Variational Autoencoders (VAE), נדבר מעט על הורדת מימדים, לאחר מכן נסביר מהו Autoencoders, כיצד הוא עובד ומה החסרונות שלו, ומשם נעבור ל-VAE.
Dimensionality Reduction
במקרים רבים, הדאטה אותו רוצים לנתח הוא בעל מימד גבוה, כלומר, לכל דגימה יש מספר רב של פיצ’רים, כאשר בדרך כלל לא כל הפיצ’רים משמעותיים באותה מידה. לדוגמא – מחיר מניה של חברה מסוימת מושפע ממספר רב של גורמים, אך ככל הנראה גובה ההכנסות של החברה משפיע על מחיר המניה הרבה יותר מאשר הגיל הממוצע של העובדים. דוגמא נוספת – במשימת חיזוי גיל של אדם על פי הפנים שלו, לא כל הפיקסלים בתמונת הפנים יהיו בעלי אותה חשיבות לצורך החיזוי. כיוון שקשה לנתח דאטה ממימד גבוה ולבנות מודלים עבור דאטה כזה, הרבה פעמים מנסים להוריד את המימד של הדאטה תוך איבוד מינימלי של מידע. בתהליך הורדת המימד מנסים לקבל ייצוג חדש של הדאטה בעל מימד יותר נמוך, כאשר הייצוג הזה מורכב מהמאפיינים הכי משמעותיים של הדאטה. יש מגוון שיטות להורדת המימד כאשר הרעיון המשותף לכולן הוא לייצג את הדאטה במימד נמוך יותר, בו באים לידי ביטוי רק הפיצ’רים המשמעותיים יותר.
הייצוג החדש של הדאטה נקרא הייצוג הלטנטי או הקוד הלטנטי, כאשר יותר קל לעבוד איתו במשימות שונות על הדאטה מאשר עם הדאטה המקורי. בכדי לקבל ייצוג לטנטי איכותי, ניתן לאמן אותו באמצעות decoder הבוחן את יכולת השחזור של הדאטה. ככל שניתן לשחזר בצורה מדויקת יותר את הדאטה מהייצוג הלטנטי, כלומר אובדן המידע בתהליך הוא קטן יותר, כך הקוד הלטנטי אכן מייצג בצורה אמינה את הדאטה המקורי.
תהליך האימון הוא דו שלבי: דאטה עובר דרך encoder, ולאחריו מתקבל
, כאשר
לאחר מכן התוצאה מוכנסת ל-decoder בכדי להחזיר אותה למימד המקורי, ולבסוף מתקבל
אם לאחר התהליך מתקיים
אז למעשה לא נאבד שום מידע בתהליך, אך אם לעומת זאת
אז מידע מסוים אבד עקב הורדת המימד ולא היה ניתן לשחזר אותו במלואו בפענוח. באופן אינטואיטיבי, אם אנו מצליחים לשחזר את הקלט המקורי מהייצוג של במימד נמוך בדיוק טוב מספיק, כנראה שהייצוג במימד נמוך הצליח להפיק את הפיצ’רים המשמעותיים של הדאטה המקורי.
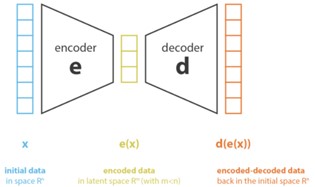
איור 1. ארכיטקטורת encoder ו-decoder.
כאמור, המטרה העיקרית של השיטות להורדת מימד הינה לקבל ייצוג לטנטי איכותי עד כמה שניתן. הדרך לעשות זאת היא לאמן את זוג ה-encoder-decoder השומרים על מקסימום מידע בעת הקידוד, וממילא מביאים למינימום את שגיאת שחזור בעת הפענוח. אם נסמן בהתאמה E ו-D את כל הזוגות של encoder-decoder האפשריים, ניתן לנסח את בעיית הורדת המימד באופן הבא:
כאשר הוא שגיאת השחזור שבין הדאטה המקורי לבין הדאטה המשוחזר.
אחת השיטות השימושיות להורדת מימד שאפשר להסתכל עליה בצורה הזו היא Principal Components Analysis (PCA). בשיטה זו מטילים (בצורה לינארית) דאטה ממימד n למימד m על ידי מציאת בסיס אורתוגונלי במרחב ה-m מימדי בו המרחק האוקלידי בין הדאטה המקורי לדאטה המשוחזר מהייצוג החדש הוא מינימלי.
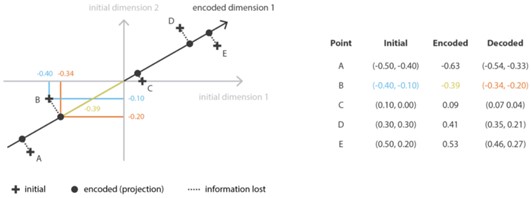
איור 2. דוגמא להורדת מימד בשיטת PCA.
במונחים של encoder-decoder, ניתן להראות כי אלגוריתם PCA מחפש את ה-encoder שמבצע טרנספורמציה לינארית על הדאטה לבסיס אורתוגונלי במימד נמוך יותר, שיחד עם decoder מתאים יביא לשגיאה מינימלית במונחים של מרחק אוקלידי בין הייצוג המקורי לבין זה המשוחזר מהייצוג החדש. ניתן להוכיח שה- encoder האופטימלי מכיל את הווקטורים העצמיים של מטריצת ה-covariance של מטריצת ה-design, וה-decoder הוא השחלוף של ה-encoder.
Autoencoders (AE)
ניתן לקחת את המבנה של ה- encoder-decoder המתואר בפרק הקודם ולהשתמש ברשת נוירונים עבור בניית הייצוג החדש ועבור השחזור. מבנה זה נקרא Autoencoder:
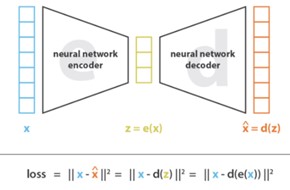
איור 3. Autoencoder – שימוש ברשתות נוירונים עבור הורדת המימד והשחזור.
באופן הזה, הארכיטקטורה יוצרת צוואר בקבוק לדאטה, שמבטיח שרק המאפיינים החשובים של הדאטה, שבאמצעותם ניתן לשחזר אותה בדיוק טוב, ישמשו לייצוג במרחב הלטנטי. במקרה הפשוט בו בכל רשת יש רק שכבה חבויה אחת והיא לא משתמשת בפונקציות אקטיבציה לא לינאריות, ניתן לראות כי ה-autoencoder יחפש טרנספורמציה לינארית של הדאטה באמצעותו ניתן לשחזרו באופן לינארי גם כן. בדומה ל-PCA, גם רשת כזו תחפש להוריד את המימד באמצעות טרנספורמציות לינאריות של הפיצ’רים המקוריים אך הייצוג במימד נמוך המופק על ידה לא יהיה בהכרח זהה לזה של PCA, כיוון שלהבדיל מ-PCA הפיצ’רים החדשים (לאחר הורדת מימד) עשויים לצאת לא אורתוגונליים (-קורלציה שונה מ-0).
כעת נניח שהרשתות הן עמוקות ומשתמשות באקטיבציות לא לינאריות. במקרה כזה, ככל שהארכיטקטורה מורכבת יותר, כך הרשת יכולה להוריד יותר מימדים תוך יכולת לבצע שחזור ללא איבוד מידע. באופן תיאורטי, אם ל- encoder ול-decoder יש מספיק דרגות חופש (למשל מספיק שכבות ברשת נוירונים), ניתן להפחית מימד של כל דאטה לחד-מימד ללא איבוד מידע. עם זאת, הפחתת מימד דרסטית שכזו יכולה לגרום לדאטה המשוחזר לאבד את המבנה שלו. לכן יש חשיבות גדולה בבחירת מספר המימדים שבתהליך, כך שמצד אחד אכן יתבצע ניפוי של פרמטרים פחות משמעותיים ומצד שני המידע עדיין יהיה בעל משמעות למשימות downstream שונות. ניקח לדוגמא מערכת שמקבלת כלב, ציפור, מכונית ומטוס ומנסה למצוא את הפרמטרים העיקריים המבחינים ביניהם:
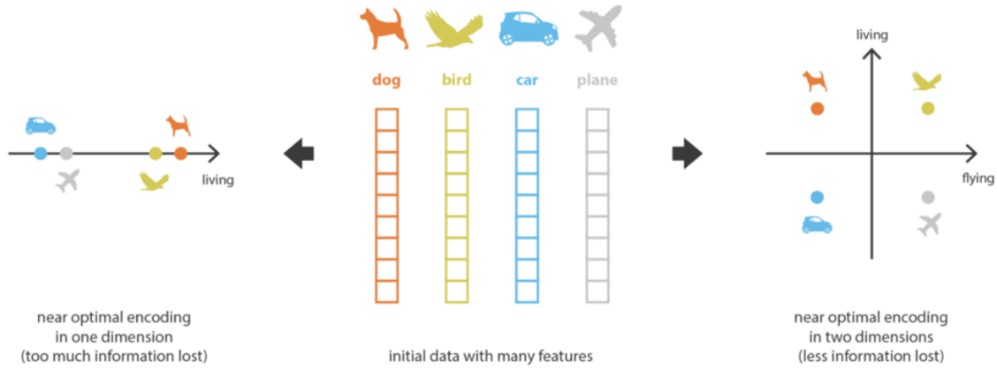
איור 4. דוגמא לשימוש ב-Autoencoder.
לפריטים אלו יש הרבה פיצ’רים, וקשה לבנות מודל שמבחין ביניהם על סמך כל הפיצ’רים. מעבר ברשת נוירונים יכול להביא לייצוג של כל הדוגמאות על קו ישר, כך שככל שפרט מסוים נמצא יותר ימינה, כך הוא יותר “חי”. באופן הזה אמנם מתקבל ייצוג חד-מימדי, אבל הוא גורם לאיבוד המבנה של הדוגמאות ולא באמת ניתן להבין את ההפרדה ביניהן. לעומת זאת ניתן להוריד את המימד לדו-מימד ולהתייחס רק לפרמטרים “חי” ו”עף”, וכך לקבל הבחנה יותר ברורה בין הדוגמאות, וכמובן שהפרדה זו היא הרבה יותר פשוטה מאשר הסתכלות על כל הפרמטרים של הדוגמאות. דוגמא זו מראה את החשיבות שיש בבחירת המימדים של ה-encoder.
Variational AutoEncoders (VAE)
ניתן לקחת את ה- AE ולהפוך אותו למודל גנרטיבי, כלומר מודל שמסוגל לייצר בעצמו דוגמאות חדשות שאכן מתפלגות כמו הפילוג של הדאטה המקורי. אם מדובר בדומיין של תמונות למשל, אז נרצה שהמודל יהיה מסוגל לייצר תמונות שנראות אותנטיות ביחס לדאטה סט עליו אומן. הרשתות של ה-AE מאומנות לייצג את הדאטה במימד נמוך, שלוקח בחשבון את הפיצ’רים העיקריים, ולאחר מכן לשחזר את התוצאה למימד המקורי, אך הן אינן מתייחסות לאופן בו הדאטה מיוצג במרחב הלטנטי. אם יוגרל וקטור כלשהו מהמרחב הלטנטי – קרוב לוודאי שהוא לא יהווה ייצוג שקשור לדאטה המקורי, כך שאם היינו מכניסים אותו ל-decoder, סביר שהתוצאה לא תהיה דומה בכלל לדאטה המקורי. למשל אם AE אומן על סט של תמונות של כלבים ודוגמים וקטור מהמרחב הלטנטי שלו, הסיכוי לקבל תמונת כלב כלשהו לאחר השחזור של ה-decoder הינו אפסי.
כדי להתמודד עם בעיה זו, ניתן להשתמש ב-Variational AutoEncoders (VAE). בשונה מ-AE שלוקח דאטה ובונה לו ייצוג ממימד נמוך, VAE קובע התפלגות פריורית למרחב הלטנטי z – למשל התפלגות נורמלית עם תוחלת 0 ומטריצת II covariance. בהינתן התפלגות זו, ה-encoder מאמן רשת המקבלת דאטה x ומוציאה פרמטרים של התפלגות פוסטריורית z|x , מתוך מטרה למזער כמה שניתן את ההפרש בין ההתפלגויות z ו- z|x . לאחר מכן דוגמים וקטורים מההתפלגות הפוסטריורית z|x (הנתונה על ידי הפרמטרים המחושבים ב-encoder), ומעבירים אותם דרך ה-decoder כדי לייצר פרמטרים של ההתפלגות z|x . חשוב להבהיר שאם הדאטה המקורי הוא תמונה המורכבת מאוסף של פיקסלים, אזי במוצא יתקבל x|z לכל פיקסל בנפרד ומההתפלגות הזו דוגמים נקודה והיא תהיה ערך הפיקסל בתמונה המשוחזרת. באופן הזה, הלמידה דואגת לא רק להורדת המימד, אלא גם להתפלגות המושרית על המרחב הלטנטי. כאשר ההתפלגות המותנית במוצא x|z טובה, קרי קרובה להתפלגות המקורית של x, ניתן בעזרתה גם ליצור דוגמאות חדשות, ובעצם מתקבל מודל גנרטיבי. כאמור, ה-encoder מנסה לייצג את הדאטה המקורי באמצעות התפלגות במימד נמוך יותר, למשל התפלגות נורמלית עם תוחלת ומטריצת covariance:
חשוב לשים לב להבדל בתפקיד של ה-decoder – בעוד שב-AE הוא נועד לתהליך האימון בלבד ובפועל מה שחשוב זה הייצוג הלטנטי, ב-VAE ה-decoder חשוב לא פחות מאשר הייצוג הלטנטי, כיוון שהוא זה שהופך את המערכת למודל גנרטיבי.
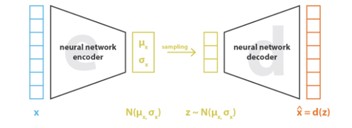
איור 5. ארכיטקטורה של VAE.
לאחר שהוצג המבנה הכללי של VAE, ניתן לתאר את תהליך הלמידה, ולשם כך נפריד בשלב זה בין שני החלקים של ה-VAE. ה-encoder מאמן רשת שמקבלת דוגמאות מסט האימון, ומנסה להפיק מהן פרמטרים של התפלגות הקרובים כמה שניתן להתפלגות פריורית , שכאמור נקבעה מראש. מההתפלגות הנלמדת הזו דוגמים וקטורים חדשים ומעבירים ל-decoder. ה- decoderמבצע את הפעולה ההפוכה – לוקח וקטור שנדגם מהמרחב הלטנטי , ומייצר באמצעותו דוגמא חדשה הדומה לדאטה המקורי. תהליך האימון יהיה כזה שימזער את השגיאה של שני חלקי ה-VAE – גם שבמוצא יהיה כמה שיותר קרוב ל- המקורי, וגם ההתפלגות תהיה כמה שיותר קרובה להתפלגות הפריורית z. נתאר באופן פורמלי את בעיית האופטימיזציה ש-VAE מנסה לפתור. נסמן את הווקטורים של המרחב הלטנטי ב-z, את הפרמטרים של ה-decoder ב- , ואת הפרמטרים של ה-encoder ב-
. כדי למצוא את הפרמטרים האופטימליים של שתי הרשתות, נרצה להביא למקסימום את
, כלומר למקסם את הנראות המרבית של סט האימון תחת
. כיוון שפונקציית log מונוטונית, נוכל לקחת את לוג ההסתברות:
אם נביא למקסימום את הביטוי הזה, נקבל את ה- האופטימלי. כיוון שלא ניתן לחשב במפורש את
, יש להשתמש בקירוב. נניח וה -encoder הוא בעל התפלגות מסוימת
(מה ההסתברות לקבל את z בהינתן x בכניסה). כעת ניתן לחלק ולהכפיל את
ב –
:
כאשר אי השוויון האחרון נובע מאי-שוויון ינסן, והביטוי שמימין לאי השיוויון נקרא Evidence Lower BOund . ניתן להוכיח שההפרש בין ה-ELBO לבין הערך שלפני הקירוב הוא המרחק בין שתי ההתפלגויות
, והוא נקרא Kullback–Leibler divergence ומסומן ב-
:
אם שתי ההתפלגויות זהות, אזי מרחק ביניהן הוא 0 ומתקבל שוויון:
. כזכור, אנחנו מחפשים למקסם את פונקציית המחיר
, וכעת בעזרת הקירוב ניתן לרשום:
כעת ניתן בעזרת שיטת GD למצוא את האופטימום של הביטוי, וממנו להפיק את הפרמטרים האופטימליים של ה-encoder ושל ה-decoder. נפתח יותר את ה- עבור VAE, ביחס לשתי התפלגויות:
– ההסתברות ש-decoder עם סט פרמטרים
יוציא x בהינתן z.
– ההסתברות ש-encoder עם סט פרמטרים
יוציא את
בהינתן x בכניסה לפי הגדרה:
את הביטוי ניתן לפתוח לפי בייס:
הביטוי השני לפי הגדרה שווה ל-, לכן מתקבל:
הביטוי הראשון הוא בדיוק התוחלת של . תחת ההנחה ש-z מתפלג נורמלית, ניתן לרשום:
כדי לחשב את התוחלת ניתן פשוט לדגום דוגמאות מההתפלגות ולקבל:
ועבור הביטוי השני יש נוסחה סגורה:
כעת משיש בידינו נוסחה לחישוב פונקציית המחיר, נוכל לבצע את תהליך הלמידה. יש לשים לב שפונקציית המחיר המקורית הייתה תלויה רק ב-, , אך באופן שפיתחנו אותה היא למעשה דואגת גם למזעור ההפרש בין הכניסה למוצא, וגם למזעור ההפרש בין ההתפלגות הפריורית z לבין ההתפלגות z|x שבמוצא ה-encoder.
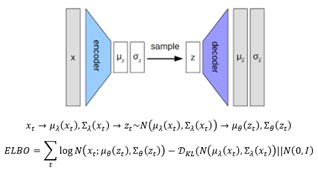
איור 6. תהליך הלמידה של VAE.
כאשר נתון סט דוגמאות , ניתן להעביר כל דוגמא ב-encoder ולקבל עבורה את
. לאחר מכן דוגמים וקטור לטנטי z מההתפלגות עם פרמטרים, מעבירים אותו ב-decoder ומקבלים את
. לאחר התהליך ניתן להציב את הפרמטרים המתקבלים ב-ELBO ולחשב את ה-Loss. ניתן לשים לב שה-ELBO מורכב משני איברים – האיבר הראשון מחשב את היחס בין הדוגמא שבכניסה לבין ההתפלגות שמתקבלת במוצא, והאיבר השני מבצע רגולריזציה להתפלגות הפריורית במרחב הלטנטי. הרגולריזציה גורמת לכך שההתפלגות במרחב הלטנטי z|x תהיה קרובה עד כמה שניתן להתפלגות הפריורית z. אם ההתפלגות במרחב הלטנטי קרובה להתפלגות הפריורית, אז ניתן בעזרת ה-decoder ליצור דוגמאות חדשות, ובמובן הזה ה-VAE הוא מודל גנרטיבי.
הדגימה של z מההתפלגות במרחב הלטנטי יוצרת קושי בחישוב הגרדיאנט של ה-ELBO, לכן בדרך כלל מבצעים Reparameterization trick – דוגמים מהתפלגות נורמלית סטנדרטית, ואז כדי לקבל את z משתמשים בפרמטרים של ה-encoder:
.forward-backwardבגישה הזו כל התהליך נהיה דטרמיניסטי – מגרילים מראש ואז רק נשאר לחשב באופן סכמתי את ה
Reference:
https://towardsdatascience.com/understanding-variational-autoencoders-vaes-f70510919f73
