
הקדמה על האתגר:
האתגר פורסם על ידי חברת רפאל ועסק כמשחק שמטרתו יצירת מיירט טילים באמצעות כלים של בינה מלאכותית ולמידת מכונה.
המטרה במשחק היא להגן על שתי ערים מרקטות המשוגרות אליהן בעזרת משגר יירוט (ראה Figure 1).
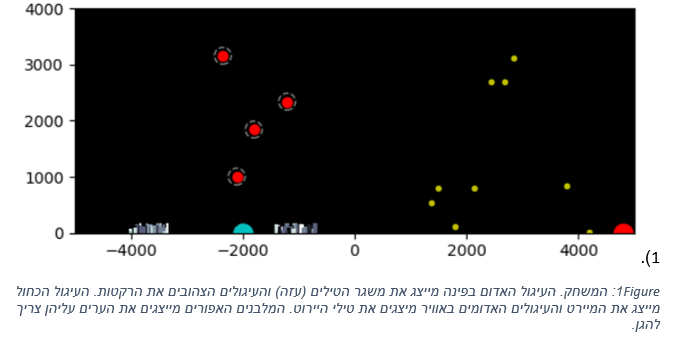
המשחק נמשך כ 1000 צעדים. בכל צעד המשגר יורה רקטה לעבר הערים בזווית אקראית.
בכל צעד ניתן לבצע אחת מ4 פעולות:
- לא לעשות כלום
- להזיז קצת את המיירט עם כיוון השעון
- להזיז קצת את המיירט נגד כיוון השעון
- לירות טיל יירוט
הניקוד במשחק הוא כדלקמן: בעת פגיעת רקטה בעיר יורדות 15 נקודות. בעת פגיעת רקטה בשטח פתוח יורדת נקודה אחת. יירוט מוצלח של רקטה מעניק ארבע נקודותובכל ירי של טיל יירוט יורדת נקודה אחת. לאחר כל צעד הסביבה מחזירה את סך הניקוד שנצבר עד כה (score).
המשחק מכיל מספר אתגרים מרכזיים:
- הdynamics של המשחק מורכבים לאלגוריתם hand-coded
- ה state space של המשחק לא קבוע– כמות הרקטות וטילי היירוט משתנה כל הזמן.
- Sparse reward– הסיכוי לירי מוצלח קטן משמעותית מהסיכוי לפספס. כלומר, סביר שהסוכן ילמד מהר שעדיף להימנע מירי.
- Reward assigning– גם במקרה והסוכן ירה נכון, התגמול על ירי מוצלח מגיע רק בדיעבד ויהיה לסוכן קשה להבין מה גרם לאותו משוב חיובי. בנוסף, פגיעה של רקטה בעיר גוררת תגמול שלילי גדול באופן מידי, ותגרום לסוכן לחשוב שהוא עשה משהו רע בצעד שלפני הפגיעה (פצצה עוינת=רקטה, טיל כיפת ברזל=טיל).
פתרון Model Free
בכדי להימנע מהגדרות מדוייקות של המערכת, החלטתי לאמן את הסוכן ע”י reinforcement learning. לצורך כך, השתמשתי באלגוריתם PPO עם מימוש הזה. הגדרתי סבב של למידה (cycle) כ10 episodes (10000 תצפיות) ואז למידה עליהם של 10 epochs. לצורך נוחות, בניתי wrapper למשחק כך שהסביבה תתפקד כמו סביבת RL סטנדרטית. את התגמול הגדרתי להיות השינוי בscore. לצורך האימון יצרתי שתי סביבות:Train env ו Test_env.
סביבת הבחינה זהה לחלוטין למשחק המקורי ולא הפעלתי עליה שום מניפולציה לא חוקית (ז”א לא שיניתי את כללי המשחק). עם זאת, בסביבת האימון ביצעתי מספר שינויים על מנת לזרז את הלמידה ולהכווין את הסוכן לכיוון ההתנהלות האופטימלית. גם לקובץ המשחק עצמו יצרתי שיכפול בו ביצעתי מספר מניפולציות עליהן ארחיב בהמשך. העיקרון שהנחה אותי בבחירת ועיצוב המניפולציות היה שלאחר האימון, הסוכן יוכל לשחק בסביבה המקורית.
ייצוג רקטות וטילים
בכדי להתחיל וליצר איזשהו baseline, צריך דבר ראשון למצוא דרך להזין את ה-state לרשת נוירונים. זו לא בעיה פשוטה במיוחד מאחר וגודל הקלט משתנה מצעד לצעד. אני מאמין שלרוב האנשים זה היה החלק הבעייתי ביותר באתגר. הפתרון המיידי והנאיבי הוא פשוט לאמן את הסוכן על התמונה של המשחק עם כמה שכבות CNN בתחילת הרשתות. פתרון זה נכשל חרוצות. התמונה מורכבת באופן לא הכרחי. אפשר, במקום זה, להכניס לרשתות תמונות הרבה יותר אינפורמטיביות.
חשוב לשים לב שהסוכן צריך לרכוש ידע דומה גם עבור הרקטות וגם עבור הטילים.
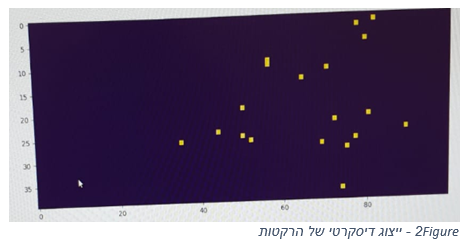
עיקרון זה הנחה את הניסיון הבא שלי – יצרתי תמונות נפרדות של רקטות וטילים, כל תמונה בגודל
של 40X100 פיקסלים (כל פיקסל מתאר גודל של 100X100 מטר) ומתארת את המצב הנוכחי של המערכת מבחינת רקטות / טילים בהתאמה (ראה figure 2).
בכל רגע נתון החזקתי את שלושת המפות האחרונות של הסביבה (כל מפה בchannel אחר) על מנת לאפשר הבנה של המהירות והתאוצה. כלומר, המצב של הרקטות והטילים תואר על ידי שני tensors בגודל של 40X100X3. מעכשיו אקרא לטנזוריםהאלה ‘תמונת רקטות’ ו’תמונת טילים’. כפי שציינתי, הניתוח של שתי התמונות דומה מבחינת כישורים שהרשת צריכה לפתח. לפיכך, בניתי רשת CNNאחת אליה הזנתי את תמונת הרקטות ותמונת הטילים בנפרד.
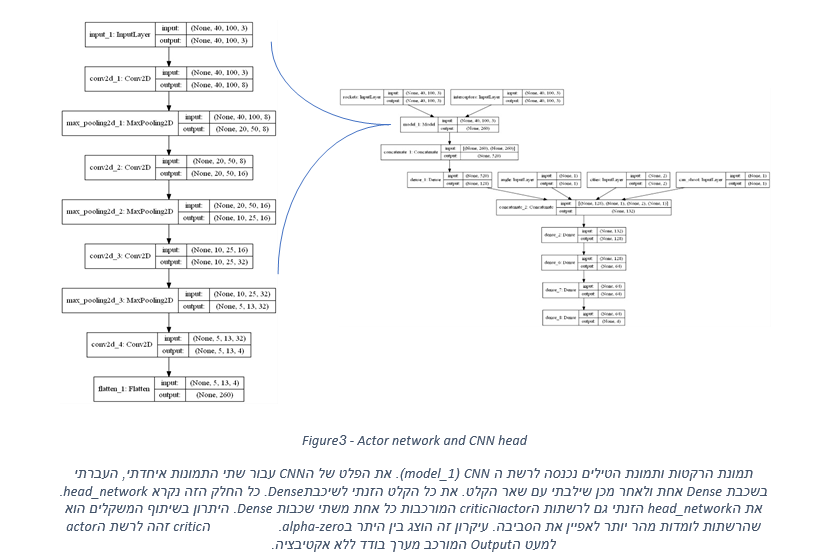
לאחר העיבוד של התמונות עם רשת הCNN, הכנסתי את הפלט של שתי התמונות לשכבת Dense עם אקטיבצייתtanh שאמורה להוציא עיבוד מוכן של מיקומי הרקטות והטילים ולפלט זה הצמדתי גם את שאר הקלט. מאחר והממדים של שאר הקלטים קבועים (מיקום הערים, זווית המיירט והמשתנה שמודיע האם ניתן לירות), אין בעיה להכניס אותו ללא עיבוד (מלבד נרמול של הערכים לטווח [1,1-]). את כל הקלט המעובד העברתי בשכבת Dense אחת. הפלט של השכבה מתאר את המצב הכולל של המערכת ואותו הזנתי לרשתות הactorוהcritic-. היתרון של שיטה זו היא שבעקבות שיתוף המשקלים (ומאחר ורשת הCNN צריכה לעשות עבודה דומה עבור שתי התמונות), הרשתות אמורות ללמוד מהר יותר. את הגרפים של רשת הActor וה-CNN ניתן לראות בfigure3.
ם זאת, גם שיטה זו לא עבדה. הסוכן הצליח לפעמים להגיע לציון חיובי, אבל לרוב נשאר אי-שם רחוק ב100- ומטה. ההנחה שלי היא שרשת הCNN לא הצליחה ללמוד לפרש את התמונות. כלומר, צריך למצוא ייצוג אחר של הרקטות והטילים.
החלטתי להימנע משילוב של רשת CNN באלגוריתם הRL. הבעיה קשה מספיק גם ככה, הלמידה של הייצוג כנראה “שברה” את הסוכן. החלטתי להשתמש בvariational auto-encoder(VAE) ללמוד ייצוג יעיל של המפות (תזכורת – מפה היא המצב הנוכחי של הטילים/רקטות). אימנתי את הVAE על 150K מפות של הסביבה (75K מפות של רקטות ו 75K של טילים) והגדרתי את המימד של ווקטור הייצוג להיות בגודל 100. כלומר, הVAE צריך היה ללמוד לייצג תמונה של 40X100X1 כווקטור עם 100 מימדים ולשחזר ממנו את התמונה המקורית. הניסיון הראשון לא הצליח. מאחר והרוב מוחלט של הפיקסלים הם 0, הVAE התכנס לאופטימום לוקאלי בו הוא פשוט מחזיר תמונה ריקה ונמנע לחלוטין מלנסות ולהגדיר איפה יש טילים. בכדי לתקן זאת, החלטתי לייצג את המצב כheat-map סביב הטילים והרקטות. גם כאן, יצרתי מפה נפרדת לטילים ולרקטות (ראה figure 4).
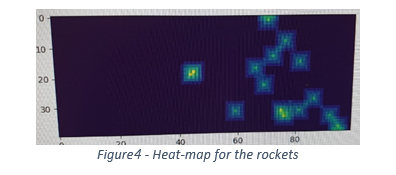
בכדי ליצור את ה heat-maps פשוט הרצתי את המפות המקוריות שיצרתי דרך קונבולוציה עם פילטרים קבועים של מטריצת אחדות בגדלים [7,5,3,1] וstrides=1, וסכמתי את התוצאות. כל קונבולוציה כזו יוצרת ריבוע של אחדות סביב הטיל בגודל מתאים וסכימה שלהם יוצרת פירמידה
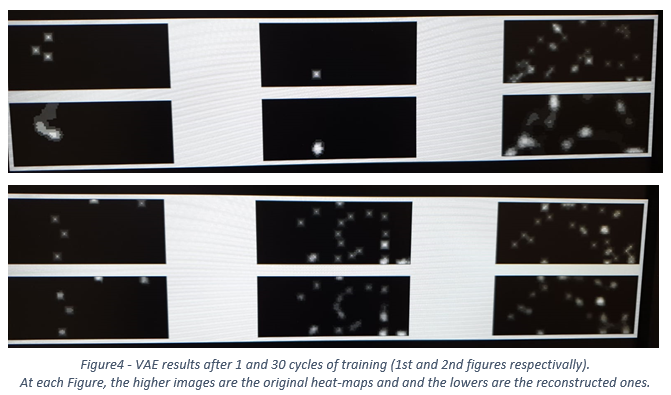
סביב הטיל. כעת, לאחר אימון, הVAE הצליח לייצר ייצוג לא רע של הטילים (ראה Figure 4,5).
אחרי שאימנתי את הVAE, החלפתי את שכבות הCNN בשכבת Dense פשוטה. שכבה זו מקבלת מקבץ של שלושה ווקטורים באורך 100 (שוב, הייצוג של המערכת לאורך 3 [1]timesteps) ומצמצמת אותם לווקטור של 128 מימדים. השתמשתי בשכבה זו עבור הרקטות והטילים בנפרד. את הפלט איחדתי לווקטור של 256 מימדים, והזנתי לעוד שכבת Dense עם אקטיבצייתtanh ופלט של 128 מימדים שמתאר את כל המצב של המערכת מבחינת רקטות וטילים. שאר הרשתות נשארו כמקודם (איור 2). גם כעת הביצועים לא היו מדהימים, אבל לפחות יש לי מסגרת לריצות. כעת הגיע הזמן לחשוב קצת יותר במונחים של למידת חיזוקים ואיך להקל על הסוכן.
Sparse Rewards
הסיכוי שירי של הסוכן יוביל למשוב חיובי הוא די נמוך. לפיכך, הסוכן לומד בשלב מוקדם שירי זו פעולה לא משתלמת, ונמנע ממנה לחלוטין. על מנת לתקן את הרושם הזה, החלטתי להשתמש בשיטה של Curriculum learning. בסביבה שסופקה על ידי רפאל יש פרמטר בשם prox_radius (פרמטר זה מגדיר את המרחק הנדרש בין הטיל לרקטה על מנת שהרקטה תתפוצץ כשהערך המקורי עומד על 150 מטר). על ידי שינוי של ערך זה, אני יכול להקל או להקשות על הסוכן. על מנת ללמד את הסוכן שירי זה דבר חיובי, אני מתחיל את האימון עם prox_radius=2000. רדיוס כל כך גדול מלמד את הסוכן שלירות זה דבר חיובי, אך לא מלמד אותו לכוון. על מנת לתקן את זה, כל פעם שהסוכן מגיע לרמת ביצועים מסויימת (אני הגדרתי את הגבול להיות score ממוצע גדול מ0 על פני 10 episodes) אני מכפיל את הרדיוס בפאקטור דעיכה (0.9) עד שהרדיוס יגיע חזרה ל150. שינוי כזה הוא חוקי כי לאחר הלמידה, הסוכן יכול לשחק בסביבה המקורית ללא שינוי.
Reward Assigning
פונקציית התגמול הישירה (השינוי בscore) לא כל כך יעילה, כי מאוד קשה לסוכן לדעת איזו פעולה אחראית לכל תגמול (גם חיובי וגם שלילי), מאחר והתגמול על ירי מוצלח מגיע רק לאחר מספר צעדים ומוצמד לפעולה שלא השפיעה עליו כלל. בנוסף, גם העונש על פגיעה בעיר הוא לא אינפורמטיבי, מאחר והוא מוצמד לפעולה שלא יכלה למנוע אותה. לפיכך, החלטתי לעצב פונקציית תגמול משלי (גם זה שינוי חוקי, מאחר ובמהלך הtest אין כלל התייחסות לתגמול). הוספתי לאובייקט world רשימה בשם reward שנבנתה במהלך הפרק ובסוף (לאחר 1000 צעדים) הוחזרה לסוכן. השינוי הראשון והבסיסי ביותר היה להכניס את התגמול על יירוט מוצלח לreward של הstep בו הטיל נורה. בכדי לעשות זאת, הוספתי לכל טיל שדה נוסף בו שמרתי את הצעד בו הוא נורה ובמידה והיה יירוט, עידכנתי את רשימת הrewards בindex המתאים.
השינוי השני היה לבטל כל משוב שלילי על פגיעה (בעיר או בשטח פתוח) במקום זה, הגדרתי לכל רקטה שדה בינארי המציין האם רקטה זו תיפגע בעיר או לא. יש לרקטה שיטה שנקראת update לעדכון המקום. יצרתי שיטה חדשה שמסמלצת את התנועה עם update עד לפגיעה בקרקע ובודקת אם זה פגע בעיר.עכשיו במקום להעניש פגיעה בעיר, נתתי בונוס נוסף של 15 נקודות לירי טיל שהוריד רקטה שהיתה אמורה לפגוע בעיר. בצורה כזו לסוכן הרבה יותר קל לתעדף פגיעה ברקטות מסוכנות כי התגמול הוא מידי.
בעיה נוספת שהיתה היא המגבלות על הירי. הסוכן יכול לירות רקטה רק אחת לכל 8 צעדים (הטעינה לוקחת 3 שניות). מאחר ואין לסוכן שום אינדיקציה מתי הוא יכול לירות ומתי לא, זה מוסיף variance לvalue שהסוכן מנסה ללמוד. ההגדרה במשחק היא מאוד מדוייקת ואין שום סיבה למנוע את הידע הזה מהסוכן. לצורך כך הגדרתי קלט נוסף –can_shoot, ששווה 1 אם הסוכן יכול לירות (עברו 7 צעדים מאז הירי האחרון) ו0 אחרת. היתרון של קלט כזה הוא שהוא מוריד את האקראיות מבחינת הסוכן ומאפשר אומדן מדוייק יותר של התוצאה של פעולות.
[1]על מנת להגביר את ההבדל בין הווקטורים, החלטתי לא להשתמש במצבים עוקבים, אלא בקפיצות של 3 time-steps. כלומר, הזנתי את הווקטור של המצב הנוכחי, לפני 3 צעדים ולפני 6 צעדים.
_______________________________
[1]על מנת להגביר את ההבדל בין הווקטורים, החלטתי לא להשתמש במצבים עוקבים, אלא בקפיצות של 3 time-steps. כלומר, הזנתי את הווקטור של המצב הנוכחי, לפני 3 צעדים ולפני 6 צעדים.
עם זאת, עדיין הסוכן לא למד מספיק טוב. הסוכן תמיד קיבל ציון גבוה באזור ה300 בשני הסבבים הראשונים של אימון בהם רדיוס הפגיעה עמד על 2000 ו 1800 (אחרי הכל, הוא יירט כמעט את כל הרקטות), אבל אחרי בערך שני סבבי למידה הוא ירד באופן מידי לאזור ה-500. הפעלתי את הrender וגיליתי שהסוכן פשוט מחליט משום מה להימנע לחלוטין מירי. אחרי כמה ניסויים גיליתי שאם אני הופך את הloss של הactor ואומר לו למזער את ה advantage, הסוכן דווקא מצליח לא רע בכלל ומגיע עד לרדיוס של בערך 400 עם ציונים גבוהים (50-100 ומעלה) ואז מתחיל להיכשל. פה חשדתי.
אחרי בערך 45 דקות של בהייה בתקרה, חשיבה ב over-clocking ודמיון אישי מודרך בו אני מנסה לראות את העולם מנקודת מבטו של הסוכן, הגעתי להארה!
PPO לא אוהב Curriculum Learning!!!!!
כן, אני יודע, זה קצת הלם, אבל תכלס זה הגיוני. אם רוצים לעבוד עם PPO (ולצורך העניין, כל אלגוריתם שמבוסס על Advantage) ביחד עם Curriculum learning, צריך לעשות את זה מאוד בזהירות. אני אסביר – הactor מחליט אילו פעולות לתעדף על ידי השאלה האם הם הניבו תוצאה טובה מהמצופה או לא. אם הcritic התאמן בעולם פשוט יותר בו קל יותר לקבל משוב גבוה (כמו עולם בו הרדיוס של הטילים גדול יותר וקל לפגוע ברקטות), הוא יגיד לactor שהצפי גדול יותר ממה שהוא אמור להיות, ולפיכך נקבל שהadvantageעל ירי יהיה כמעט תמיד שלילי. ככל שפעולה היתה מתגמלת יותר בעולם הקודם, כך צפויה לcritic אכזבה חמורה יותר. הcritic התאכזב מאוד מהתוצאה של ירי וגרם לactor להימנע ממנו לחלוטין. כשחושבים על זה, זה לא כל כך מפתיע. כמו שאומרים, “כגודל הצפייה, כך גודל האכזבה” ולכן גם נרמול של הAdvantage לא עזר כאן (האכזבה מירי היתה גדולה מהאכזבה מהימנעות מירי).
שני הפתרונות היחידים שעזרו היו לאפס את שכבת הoutput של הcritic כל פעם שמורידים את הרדיוס (פעולה מעט אגרסיבית שעדיף להימנע ממנה) או להוריד מאוד את קצב השינוי של הסביבה, כדי שלcritic יהיה זמן להתאקלם. לאחר שינוי קצב הדעיכה של הרדיוס מ0.9 ל 0.98, נראה היה שהעניין הסתדר.
עם זאת, הסוכן עדיין התקשה להגיע לרדיוס האמיתי (150) של הבעיה ונתקע באזור ה200.
באיחור נורא, החלטתי לבדוק את המימוש של PPO שלקחתי מgithub. מסתבר שהמימוש הזה די גרוע ונכשל אפילו בפתרון בעיות סטנדרטיות של Gym…
פה אמרתי נואש, לאור העובדה שנשארו רק כמה שעות לתחרות.
אם היה לי עוד כמה ימים, השיפורים העיקריים שהייתי בודק היו:
- כמובן, חיפוש מימוש אחר.
- שיפור של הרפרזנטציה. אולי אימון נוסף של הVAE על יותר נתונים עם פחות תלות בניהם. הכנסתי לסט שלי רק תמונה אחת כל 50 timesteps מפוצלת ל3 מפות), אבל בדיעבד קלטתי שתמונת המצב מכילה 3 מפות עוקבות, מה שיצר סטים מאוד דומים אחד לשני. הייתי מתקן את זה ומכניס רק את המצב הנוכחי של המערכת במקום את 3 המצבים האחרונים.
בנוסף, אני חושב שבעתיד אבחן 2 כיוונים נוספים “בשביל הספורט”. דבר ראשון, הייתי רוצה להחליף את הרפרזנטציה בשכבה של Deep sets. כלומר, להכניס כל אחד מהטילים לרשת קטנה (שכבה או שתיים) עם output של נניח 50 נוירונים ואז לאחד את הפלט של כל הטילים בעזרת max pooling (או משהו בסגנון) על כל אחד מהממדים.
כיוון נוסף הוא לעזוב את הפתרון של end2end. יכול להיות מעניין לפצל את הבעיה ל2 סוכנים שונים:
- בחירת טיל לירוט – סוכן זה מקבל את כל הטילים באוויר ובוחר באיזו רקטה להתמקד עכשיו. כנראה הייתי מנסה לקמבן פה איזו ווריאציה של attention.
- יירוט הטיל – לאחר בחירת הרקטה, הייתי מעביר את נתוני הרקטה הבודדת הזו לסוכן שאחראי על היירוט והוא היה בוחר את רצף הפעולות עד לשחרור טיל היירוט. את הסוכן הזה הייתי מאמן בעזרת האלגוריתם HER או עם curriculum פשוט על גדלי הטילים כך שילמד לכוון ולירות כמו שצריך.
חוץ מזה, אני חושב הגיע הזמן לעבור לPytorch. חוץ ממימוש הbaselines שבלתי אפשרי לעבוד איתו, כמעט וכל המימושים הטובים הם בPytorch.
לסיכום, היה לא קל, מתסכל ואפילו מייאש לעיתים, אבל כחוק, RL זה פשוט תענוג!
אם מישהו מעוניין בפרטים נוספים / קוד, שידבר איתי בפרטי 😊 0526429005
