
הרחבת מאגר הנתונים – Data Augmentation
אחת השיטות האפקטיביות בלמידה עמוקה להגדיל את כמות הדוגמאות איתן מאמנים רשת, נקראת Data Augmentation. הגדלת ה DB תורמת לאימון מודל מוצלח יותר וכללי יותר ובפרט להימנע מתופעת ה-overfit (כשהמודל לומד טוב מידי את הדוגמאות שמביאים לו באימון אך לא לומד על המקרה הכללי).
מאגרי נתונים הינם מצרכים מבוקשים ויקרים, אך בדרכים סינטטיות ניתן להגדיל את הקיים. הדרכים המקובלות הינן הרעשה או הפעלת טרנספורמציות כאלו שלא ישנו את התוכן החשוב במידע. למשל בעולם התמונות נהוג לסובב, לחתוך, לשנות רמת הארה\בהירות וכו’. בכתבה זו אציג את שיטת המחיקה האקראית הלקוחה ממאמר זה.

https://zhuanlan.zhihu.com/p/44363288
המוטיבציה לשיטת המחיקה האקראית
במשימות לסיווג תמונה או גילוי אובייקט בתמונה, רשתות לעיתים קרובות מסתמכות על חלק אחד דומיננטי המאפיין את האובייקט. למשל אם המשימה היא לסווג תמונה האם קיים בה אדם או לא, סביר שהרשת תקבל את רוב ההחלטה על סמך מציאת הפנים של אותו אדם, מהסיבה הפשוטה שזה חלק גוף הכרחי לקיומו של אדם, הוא ייחודי בצורתו ונדיר שיהיה מוסתר. כך למרות שהרשת היתה יכולה ללמוד חלקי גוף אחרים כמו ידיים או רגליים, היא “מסתפקת” בחיפוש אחר פנים, ומקבלת את ההחלטה על סמך מציאתם. רשת כזו תתקשה למצוא אדם כאשר הפנים שלו מסובבות או מוסתרות ע”י אובייקט אחר, למרות שלנו כבני אדם קל מאוד לזהות את שאר חלקי הגוף שמרמזים שהאדם נמצא בתמונה.
בתמונות הבאות מתוך המאגר של nanit אפשר לזהות בקלות את התינוק, אך לרשת שמסתמכת בעיקר על תווי הפנים יהיה קל לזהות את התינוק בתמונה השמאלית וקשה לזהות אותו בתמונה הימנית, למראות מאפיינים מובהקים כמו ידיים ורגליים.

הרחבה באמצעות מחיקה אקראית
במאמר מציעים לתקוף את הבעיה בצורה ישירה: אם הרשת מסתמכת על אזור מסוים, נבצע הרחבה ע”י מחיקה אקראית של אותו אזור מהתמונה. כלומר בהסתברות כלשהי למשל 50%, בתמונה הנכנסת לאימון יוסתר החלק הדומיננטי. ההסתרה יכולה לעשות ע”י צביעת הפיקסלים בצבע אחיד כלשהו או בצביעת כל פיקסל באזור בצבע אקראי. כך הרשת תיאלץ ללמוד גם חלקים אחרים באובייקט על-מנת למזער את שגיאת האימון.
בשיטה זו קיימת בעיה חדשה: איך יודעים איזה חלק יהיה הדומיננטי באובייקט? וגם אם נגלה או ננחש אותו, יש סכנה שחלק אחר יהפוך לדומיננטי והבעיה תחזור על עצמה. הפתרון הוא להסתיר כל פעם חלק אחר בתמונה באופן אקראי. בכל איטרציית אימון מלאה (epoch) נבחרים חלק מהתמונות באופן אקראי, ובכל תמונה מוגרל מלבן שערכי הפיקסלים שלו מוסתרים באופן שתואר קודם.

תודה ל Random Erasing Data Augmentation
רצוי שהמלבן שנבחר למחיקה ישקף באופן הטוב ביותר את האינפורמציה שרוצים למחוק. אם למשל יודעים שראש אדם הוא בקירוב ריבועי, כלומר יחס גובה-רוחב קרוב ל-1, ושהגודל שלו נע בין 30 ל-100 פיקסלים, נבחר מלבן אקראי שעונה על התנאים האלו. אם ידוע לנו מראש היכן האובייקט הרלוונטי, בעיקר במשימות גילוי, נבחר מלבן בתוך האובייקט. הנקודה הנכונה רלוונטית בעיקר כאשר האובייקט מהווה חלק קטן מהתמונה, ובחירת מלבן אקראי מתוך כל התמונה תפספס בחלק גדול מהמקרים את המטרה, תרתי משמע.
בתמונה הבאה אפשר לראות כמה דרכים לבחור את המלבן המוסתר. באופן אקראי מכל התמונה, מתוך האוביקטים בלבד, או שילוב: גם מתוך כל התמונה וגם מתוך האוביקטים. הדרך השלישית נתנה את התוצאות הטובות ביותר.

תודה ל Random Erasing Data Augmentation
תוצאות
להלן תרשים המתאר את שיפור הביצועים באימון מודל ResNet על מאגר תמונות Cifar-10 עם ובלי שיטת המחיקות האקראיות (Random Erasing). ניתן לראות איך ללא השגת תמונות נוספות אמיתיות לאימון, הרשת מצליחה בזיהוי בשגיאה נמוכה באופן משמעותי:
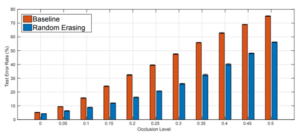
תודה ל Random Erasing Data Augmentation
קישורים
לקוד – https://github.com/zhunzhong07/Random-Erasing
למאמר – https://arxiv.org/abs/1708.04896
