מאז ומתמיד (או לפחות מאז שהתחילו להתעסק בלמידה עמוקה) אחת מהבעיות הגדולות ביותר שעמדו בפני כל אחד שמתעסק במדעי הנתונים הייתה כיול מודלים. במילים אחרות, אלו היפר-פרמטרים (פרמטרים המגדירים את המודל שאותו אנו מנסים ללמוד, כגון גודל שכבות, פונקציות הפעלה, מקדמי רגולריזציה, וכו’) מאפיינים את המודל הטוב ביותר לבעיה.
אופטימיזציה של מודלים
לאורך שנים פיתחו שיטות היוריסטיות רבות למצוא את מודל זה, אך באופן כללי כולן אומרות אותו דבר:
- עד
שמצאנו את המודל האופטימלי:
- קבע את הטווח הפרמטרים לפי השלב הקודם (בשלב הראשון בחר טווחים לפי האינטואיציה).
- אמן שורה שלמה של מודלים שבנויים מקומבינציות של פרמטרים אלו
- בחר את הפרמטרים שיצרו את המודל הטוב ביותר והשתמש בהם כדי לחדד את טווח הפרמטרים החדש שאותו רוצים לבדוק.
כמו שניתן לראות, שיטה זו מלאה בבעיות, החל מכך שהפרמטרים נקבעים ע”י ניחוש (או ניחוש חכם, אבל בכל זאת ניחוש) וכלה בכך שהתהליך לוקח זמן ומאמץ רב. לאחרונה התחיל מחקר תיאורטי למציאת המודל האופטימלי בצורה חכמה יותר. אחת ממובילי מחקר זה הם גוגל, שבנו שיטה חדשה למציאת מודלים אופטימליים שמבוססת על עיקרון בודד:

כלומר, כמו כל בעיה שעליה אנו עובדים במדעי הנתונים – אם אנחנו לא יודעים לפתור את הבעיה ננסה להשתמש בלמידת מכונה כדי לפתור אותה…
למידת מכונה מאפטמת (מיטיבה) למידת מכונה
גוגל, במאמר פורץ דרך, פיתחו מערכת חדשה בשם AdaNet שמשתמשת בכוח של למידת מכונה כדי לבנות מודלים אופטימליים. המעלה הגדולה ביותר של המערכת – היא מבוססת קוד פתוח ומשתלבת באופן חלק יחד עם TensorFlow, המערכת הקיימת של גוגל לכתיבת מודלים ללמידה עמוקה.
הרעיון הבסיסי של גוגל הוא פשוט – על מנת למצוא מודלים אופטימליים עלינו להוסיף מספר רב של מודלים קטנים יחד לקבלת התוצאות הטובות ביותר.
באופן כללי, שיטה זו נקראת Ensemble Learning, והיא כבר נמצאת בשימוש על מנת לשלב מודלים חלשים יחסית לכדי מודל חזק.
ע”י שילוב מודלים קטנים, AdaNet
יכולה ללמוד מודלים גדולים ומורכבים בצורה אופטימלית.

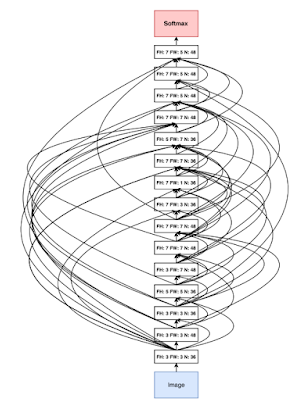
ניתן לראות באנימציה איך באופן אדפטיבי יש גדילה של שילוב של מודלים, בכל איטרציה בהתאם למדידת פונקציית המחיר המשולבת (ensembled loss function) לכל מועמד האלגוריתם בוחר את המועמד הטוב ביותר להמשיך איתו לאיטרציה הבאה. באיטרציות הבאות הרשתות הכחולות מוקפאות ורק הרשתות הצהובות מאומנות.
באלגוריתם יש אלמנט חשוב: על מנת למנוע מהמודל “לשנן” את המידע שהוא מקבל כסט אימון (overfitting) ולעודד אותו ללמוד תבניות כלליות ככל הניתן של הדאטא, המודל משתמש ברגולריזציה כפולה. החלק הראשון של הרגולריזציה הינה הרגולריזציה הרגילה אותה אנו מכירים, שמוסיפה צירוף כלשהו של משקלי המודל לפונקציית המחיר, דבר הגורם לתהליך הלמידה לשמור על משקלים קטנים יותר. הרגולריזציה השניה הינה רגולריזציה שנועדה לשמור על כך שמספר הרשתות הקטנות שמרכיבות את המודל הגדול לא יהיה מוגזם. על מנת לעשות זאת אנו מגדירים מחיר על “רשת מסובכת”, כלומר רשת שמורכבת ממספר רב של רשתות קטנות (לדוגמה, ניתן לקחת את שורש מספר הרשתות הקטנות או את שורש מספר השכבות הכולל של הרשת). הוספת מחיר זה לפונקצית המחיר הכוללת שומרת על מודלים קטנים יחסית שמכלילים את הדאטא בצורה מוצלחת יותר.
תוצאות מדווחות
התוצאות של מודל זה מרשימות במיוחד. ע”י שימוש ברשתות נוירונים פשוטות (Fully-connected feed forward) המערכת הצליחה ללמוד מודלים שמשתווים, או אפילו עולים עליהם בביצועיהם, בדר”כ ע”י שימוש בפחות פרמטרים מהמודלים הטובים ביותר שבנויות מאותו סוג רשת.
לדוגמה, על CIFAR-10, אוסף סטנדרטי לזיהוי תמונות, הצליחה המערכת שלהם יותר מהמערכות הקיימות. (להזכירכם, המודלים היחידים שהושווה הם מודלים שמכילים שכבות מלאות בלבד, תוצאות אלו לא מייצגות את המודלים הטובים ביותר שקיימים בשוק).
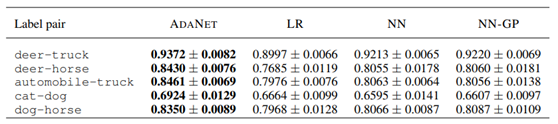
ואולי אף יותר מרשים מכך היא העובדה שהמערכת השיגה זאת ע”י מספר קטן יותר של פרמטרים במודלים שהיא בנתה:
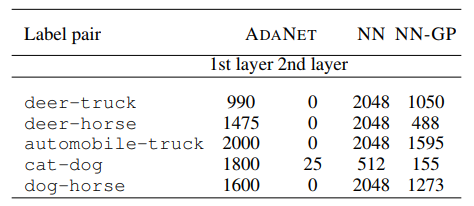
אחזור ואדגיש כי מערכת זו גמישה במיוחד וניתן להשתמש בה על מנת לבנות מודלים מכל סוג המורכבים ממגוון רחב של שכבות (כגון CNN, RNN וכו’). כותבי המאמר בחרו שלא לעשות זאת על מנת לפשט את התהליך.
מערכת זו מנסה לשנות את כל תפיסת העולם של אלו מאתנו שמבלים ימים רבים בחיפוש מודלים אופטימליים עבור בעיות. AdaNet מציגה דרך חדשה לחשוב על בעיות למידת מכונה – במקום לנסות ולמצוא את המודל הטוב ביותר על שעלינו לעשות הוא לנסח את הבעיה ולתת למחשב ללמוד עבורנו את מודל זה.
צלילה קלה לקוד
עבור המעוניינים, את הקוד המלא למערכת (כולל הוראות התקנה ודוגמות) ניתן למצוא ב- https://github.com/tensorflow/adanet .
ניתן להתקין בקלות:
$ pip install adanet
ולהשתמש בזה (כקופסה שחורה) גם די בפשטות:
head = tf.contrib.estimator.multi_class_head(10)
estimator = adanet.Estimator(
head=head,
subnetwork_generator=CNNGenerator(),
max_iteration_steps=max_iteration_steps,
evaluator=adanet.Evaluator(
input_fn=adanet_input_fn,
steps=None),
adanet_loss_decay=.99)
כאשר head מגדיר שכבת ה-softmax במוצא הרשת המשולבת. (למשל 10 מחלקות)
CNNGenerator הינה ירושה של המחלקה adanet.subnetwork.Generator שמחזירה כמה רשתות מועמדות לכל איטרציה ומבוססת על מחלקה שיורשת מ-adanet.subnetwork.Builder
ההפעלה עצמה מתבצעת ע”י קריאה ל-
tf.estimator.train_and_evaluate()
למעשה, גם את הקופסה השחורה הזו ניתן להבין די בקלות, במיוחד עבור אלו שמכירים High level APIs כדוגמת Keras. הממשק Estimator מתפקד כמו כל פונקציית fit אחרת, ומתאים את הפרמטרים בהתאם לפונקצית המחיר, שבמקרה זה ניתנת בפרמטר evaluator. הייחוד בקריאה זו לממשק הוא שאנו נותנים לרשת לבחור את תתי הרשתות בצורה דינמית מתוך האופציות שאנו מספקים בפונקציה subnetwork_generator. למי שמעוניין, ממשק זה נמצא בשימוש גם באופן כללי ב- Tensorflow וניתן ללמוד עליו כאן.
מכיוון שמערכת זו חדשה במיוחד (הגרסה העובדת הראשונה שוחררה לציבור רק באוקטובר 2018 ואפילו כעת ישנה עבודה אינטנסיבית על הקוד) השימוש בה עדיין לא נפוץ, אך אין לי ספק כי בעתיד זו תהיה הדרך בה כולנו נבנה ונאמן מודלים של למידה עמוקה.