
Google Brain הינה מחלקת המחקר של גוגל שעוסקת בלמידה עמוקה. המחלקה הוקמה ב 2011 ודוגלת במחקר חופשי. ז”א כל חוקר בקבוצה ראשי לבחור את תחום המחקר שלו תחת החזון של לשפר את חיי האנשים ולהפוך מכונות לחכמות יותר.
בכתבה זו אסקור כמה מנושאי המחקר היותר מעניינים עליהם עבדו ב Google Brain בשנת 2017 על פי הבלוג שלהם.
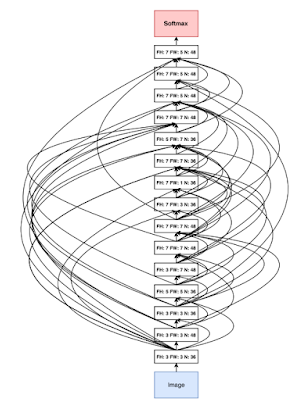
אוטומציה של למידת מכונה AutoMl – המטרה במחקר זה הוא לבנות אוטומציה לבניית פתרונות Machine Learning מבלי התערבות של חוקרים אנושיים. ז”א מדובר באלגוריתמים שבונים אלגוריתמים (בתרשים למטה ניתן לראות ארכיטקטורת רשת שנבנתה ע”י אלגוריתם) , ומסתבר שהאלגוריתמים שנבנים ע”י אלגוריתמים מצליחים לא פחות טוב מאלגוריתמים שמפתחים בני אדם. החזון של המחקר הזה הינו יצירת בינה מלאכותית אמיתית וכללית.
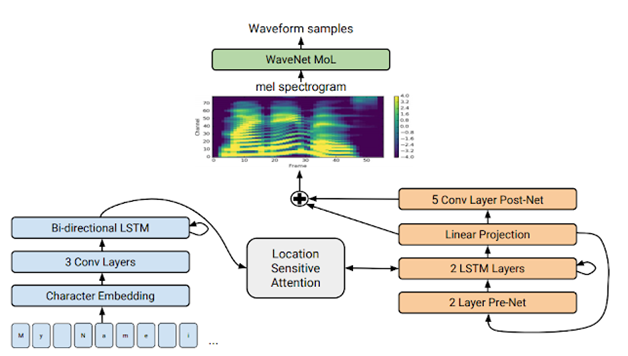
Speech Understanding and Generation – שיפור היכולות של זיהוי ושל יצירה של קול אנושי. בפרט בעיית המרת טקסט לדיבור Text to Speech בה חלה פריצת דרך כשמערכת Tacotron (תרשים המציג את הארכיטקטורה למטה) מדברת מתוך טקסט כלשהוא באופן כזה שעובר את מבחן טיורינג, ז”א שלא ניתן להבדיל אם בן אנוש או מחשב מקריא את הטקסט. האזינו להדגמה כאן!
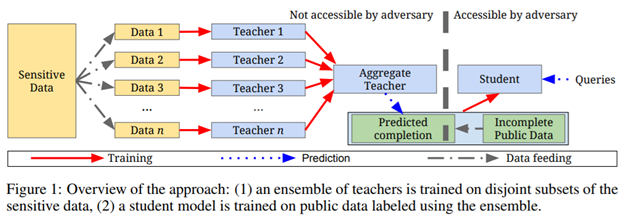
בתחום Privacy and Security –
במאמר מעניין שעוסק בפרטיות המידע החוקרים מציעים גישה בעזרתה פרויקטים המבוססים על מאגרי נתונים רגישים ופרטיים (למשל תמונות או נתונים של בדיקות רפואיות על אנשים) יוכלו לבנות מודלים מבלי שתהיה להם גישה לנתונים הרגישים. ע”פ הגישה יאומנו מודלים שנקראים “מורים” שהם כן אומנו עם database רגיש. ומודלי המורים יהיו נגישים לשימוש כקופסה שחורה (ללא גישה לפרמטרים שלהם). וכך יוכלו מהנדסים להיעזר באותם “מורים” כדי לאמן מודלים משלהם שנקראים “תלמידים” לבעיות ספציפיות אך ללא גישה למאגרי הנתונים הרגישים. האימון של התלמידים ייעשה ע”י ניסיון להתחקות אחרי תשובות המורים.
Understanding Machine Learning Systems –
הרבה מחקר נעשה כדי להבין איך רשתות למידה עמוקה עובדות, איך לפרש אותן ואיך להנגיש אותן בצורה ברורה לקהילה. בהקשר זה התאגדו Google, OpenAI, DeepMind, YC Research והשיקו מגזין אונליין בשם Distill שנועד לעזור לאנשים להבין למידת מכונה. האתר גם מספק כלים ויזואליים להמחשה של אלגוריתמים – שווה להכיר!
