בכתבה זו אראה איך אפשר עם כלים פשוטים בעולם ה Machine Learning (למידת מכונה) ניתן לנבא סיכון למתן הלוואה. הכתבה מיועדת לאנשים ללא רקע כלל ולבסוף יש גם דוגמת קוד שמיועדת למי שגם לא חושש מקצת תיכנות.
ראשית אסביר מה הכוונה לפתור בעיה זו שלא באמצעות Machine Learning, כדי להבין טוב יותר מה זה בכלל Machine Learning.
נניח שיש לנו מאפיינים של לקוח בבנק שמבקש הלוואה ועלינו להחליט אם כדי לאשר לו הלוואה או לא. המאפיינים הינם בין השאר: גובה ההלוואה המבוקשת, יש\אין משכנתא על הבית, הכנסה שנתית, ועוד ועוד… (סה”כ 86 מאפיינים כפי שנראה בהמשך בדוגמת הקוד)
אילו היינו מנסים לנבא את סיכוי החזר ההלוואה שלא באמצעות Machine Learning היינו בונים כנראה כמה תנאים המבוססים על הידע שלנו כבני אדם או יותר טוב כאנשי מקצוע פיננסיים. (מה שנקרא Feature Engineering)
למשל: אם גובה ההלוואה גדול מ 100,000 ש”ח וההכנסה השנתית של מבקש ההלוואה קטנה מ 80,000 ש”ח אז הסיכוי 0.5, אחרת הסיכוי תלוי גם במאפיינים נוספים ולכן נבדוק גם את ממוצע עיסקאות האשראי ואז אם…
ז”א אנחנו נבנה מן סט של תנאים המבוססים על הידע שלנו כדי לנבא יכולת החזר הלוואה.
אבל בעולם ה Machine Learning אנחנו נבנה מודל שיעריך את הסיכוי להחזר ההלוואה בהתבסס על נתונים. ויותר מזה, נכוונן את המודל שלנו באופן אוטומטי כך שיתאים לנתונים שבידינו. ז”א סט התנאים יקבעו לבד ולא על בסיס הידע שלנו.
כשאני אומר נתונים בהקשר זה אני מתכוון לטבלה גדולה ככל שניתן להשיג של מבקשי הלוואה (עם כל ה 86 מאפיינים לכל מועמד) שהבנק אכן אישר להם הלוואה ואנחנו יודעים מה קרה בסוף (החזירו בצורה תקינה או לא).
כשמאמנים מודל Machine Learning על Database שכזה זה נקרא Supervised Learning (לימוד מפוקח) כיוון שאנחנו כאילו “מפקחים” על המודל בזמן הלמידה. אם אלו המאפיינים של מבקש ההלוואה אזי זה מה שקרה איתו (החזיר\לא החזיר את ההלוואה). אילו היו בידינו את המאפיינים ולא את התוצאה (החזיר\לא החזיר) אז היינו בעולם ה Unsupervised Learning.
בעולם ה Supervised Learning (ז”א כשיש לנו את התשובות הנכונות) ישנם מודלים רבים המסוגלים ללמוד את הנתונים ואז לקבל נתונים חדשים (קרי מבקש הלוואה חדש שאיננו יודעים אם אכן יחזיר או לא) ואז המודל ינבא את יכולת ההחזר הלוואה שלו. כמובן יש מודלים המצליחים יותר ויש פחות – אין כמעט אף פעם 100% הצלחה. אבל אם מודל מאומן מנבא בהצלחה של נניח 70% זה כבר עשוי לחסוך כסף רב לבנק. (בטח לעומת החלופה של לאשר לכולם הלוואה)
אז כעת נכיר שני מודלים פשוטים ופופולאריים בעולם ה Supervised learning שנקראים KNN ו Logistic Regression. אך לפני זה נכתוב בצורה מפורשת איך נראים הנתונים שלנו.
הכרת הנתונים
כאמור בדוגמה שלנו הנתונים שלנו הם אוסף של מבקשי הלוואות ולכל אחד מהם 86 מאפיינים (את זה נהוג לסמן ב X1,X2,X3,…,X86 או פשוט כוקטור X) ולכל מבקש הלוואה כזה את התשובה הנכונה (שנקראת ה label ואותה נהוג לסמן ב Y) ז”א האם החזיר את ההלוואה (ניתן לזה ערך 1) או לא החזיר את ההלוואה (ניתן לזה ערך 0). הטבלה הבאה ממחישה נתונים לדוגמא:
| משכורת חודשית (X1) | גובה משכנתא (X2) | גיל (X3) | … | … | ותק בבנק (X86) | החזיר\לא החזיר (Y) |
| 10,000 | 350,000 | 37 | … | … | 4.5 | 1 |
| 17,000 | 0 | 41 | … | … | 2 | 1 |
| 13,000 | 100,000 | 35 | … | … | 3 | 0 |
| … | … | … | … | … | … | … |
מודל KNN
השם המלא של המודל הינו K Nearest Neighbor והשם מלמד על הרעיון שבו: ניבוי באמצעות הצבעה של K דוגמאות דומות לדוגמה הנבדקת.
אסביר אותו עם הדוגמה שמלווה אותנו בפוסט הזה של ניבוי יכולת ההחזר על מבקש הלוואה כלשהוא:
נקבע את K להיות ערך שלם כלשהוא, נניח 5.
ואז בהינתן מאפיינים של מבקש הלוואה חדש, נחפש את חמשת (K) מבקשי ההלוואות שיש לנו בסט הנתונים הדומים לו ביותר. (ז”א שה 86 מאפיינים שלהם קרובים ל 86 מאפיינים של מבקש ההלוואה החדש פשוט ע”י סכום ריבועי הפרשי הערכים). ואז לכל אחד מחמשת מבקשי ההלוואה שמצאנו מהנתונים שלנו אנחנו יודעים את ה label שלהם (ז”א אם הם החזירו או לא החזירו את ההלוואה). נעשה הצבעה בין חמישתם ולפי תוצאות הרוב כך ננבא את התוצאה של מבקש ההלוואה החדש. אם נניח שלושה מתוכם החזירו את ההלוואה ושניים לא, אז ננבא שמבקש ההלוואה החדש גם יחזיר (כי המאפיינים שלו דומים לשלהם).
אז זה הרעיון הכי פשוט, (שגם עובד לא רע בחלק מהמקרים) לאיך ניתן להשתמש בנתוני עבר כדי לנבא על נתון חדש.
למי שקצת יודע לכתוב קוד אז פייתון היא שפת התיכנות אולי הכי פופולארית בעולם ה Machine Learning וספציפית יש חבילה שנקראת Sklearn שבה ממומש KNN ועוד מודלים רבים של Machine Learning.
אז שתי שורות קוד מבצעות את הרעיון הנ”ל:
model = KNeighborsClassifier(n_neighbors=5)
model.fit(x, y)
אותו K ממקודם נקרא מספר השכנים n_neighbors השכנים, הנתונים שברשותינו נקראים x והתשובות הנכונות שברשותינו נקראים y.
שתי שורות הקוד הנ”ל הם ההכנה ונקראות התאמת או אימון המודל לנתונים. ושורת הקוד הבאה משתמשת במודל המאומן כדי לנבא החזר או אי החזר הלוואה על מבקש הלוואה חדש x_new:
model.predict(x_new)
מודל Logistic Regression
שוב אסביר ברמה הטכנית איך מודל הרגרסיה הלוגיסטית מנבא החזר הלוואה על בסיס ה 86 מאפיינים שיש לנו של מבקש הלוואה כלשהוא. הרעיון פה מבוסס על הפונקציה הבאה:
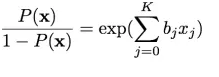
(אקספוננט של צירוף לינארי על הנתונים עם מקדמים β‘s ייתן את היחס בין ההסתברות להחזר ההלוואה לבין אי החזר ההלוואה)
אימון המודל (קרי מציאת המקדמים) מבוסס על הנתונים שבידינו וזה נעשה באמצעות שיטת שיערוך (שלא אכנס לפרטיה כאן) שנקראת Maximum Likelihood, ברמת האינטואיציה קל להסביר שאלו המקדמים שיסבירו הכי טוב שאפשר את הנתונים שבידינו.
היה אפשר להשתמש בפונקציה אחרת (לא לוג) ולמצוא את המקדמים שלה אבל הסיבה שמשתמשים דווקא בפונקציית הלוג זו כי היא נותנת פתרון שיש לו יתרון נוסף והוא מיקסום האנטרופיה של הפתרון.
ושוב ניתן להשתמש בזה באופן דומה למקודם באמצעות שתי שורות קוד בפייתון (עם חבילת Sklearn), אימון המודל (קרי מציאת המקדמים על בסיס נתונים ולייבלים קיימים x,y):
()model = LogisticRegression
model.fit(x, y)
ושימוש במודל כדי לנבא יכולת החזר של מבקש הלוואה חדש:
model.predict(x_new)
דוגמת קוד
בקישור הזה יש קוד מלא מא’ עד ת’ שממחיש טעינה של נתונים לדוגמא ואימון שני המודלים המדוברים על הנתונים. (הנתונים לקוחים מכאן)
להלן עיקרי הקוד עם הסברים:
- חבילות פייתון שיש להשתמש בהם
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
2. טעינת הנתונים
train_df = pd.read_csv(Path(‘2019loans.csv’))
test_df = pd.read_csv(Path(‘2020Q1loans.csv’))
טכניקה שקיימת בכל עולם ה Machine Learning הינה פיצול הנתונים שלנו לשתי קבוצות: קבוצת האימון (train) וקבוצת הבדיקה\ואלידציה (test).
בנתונים מקבוצת האימון נשתמש לאמן את המודל ובנתונים מקבוצת הבדיקה נשתמש לבחון את הצלחת המודל המאומן.
שתי הקבוצות חייבות להיות נפרדות (ללא חפיפה כלל) ועל שתיהן לייצג נאמנה את המציאות.
אילו הייתה בינהן חפיפה זה כאילו היינו נותנים בבחינת גמר לסטודנטים שאלות שכבר הכירו בתרגילים הבית ואז התוצאה לא הייתה הוגנת.
3. שליפת הנתונים והלייבלים
הנתונים שלנו לקוחים מקבצי אקסל ועלינו להפריד בין מאפייני מבקשי ההלוואות (x) לבין התשובה הנכונה (ה label שלהם) ז”א האם אישרו להם הלוואה בסופו של דבר או לא (y).
y_train = train_df[“loan_status”] # Take target feature for training data
X_train = train_df.drop(columns = [“loan_status”]) # Drop target from training data
:Same for testing #
y_test = test_df[“loan_status”]
X_test = test_df.drop(columns = [“loan_status”])
4. המרת משתנים קטגוריאליים
חלק מאותם 86 מאפיינים לכל מבקש הלוואה אינם משתנים מספריים אלא קטגוריאליים. ז”א הערך הוא אחד מבין כמה ערכים מוגדרים מראש. למשל מאפיין בעלות הבית (home_ownership) הינו אחד מבין: MORTGAGE, OWN או RENT.
כיוון שהמודלים שלנו עושים חישובים אריתמטיים בין מספרים עלינו להפוך משתנים קטגוריאלים למספרים וזאת עושים באמצעות שורות הקוד הבאות:
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)
המרה זו מחליפה כל משתנה קטגוריאלי לכמה משתנים בינאריים, למשל במקום המשתנה home_ownership יהיה לנו שלושה משתנים שיכולים לקבל ערכים אפס או אחד (ואיתם כבר אפשר לעשות חישובים אריתמטיים).
| home_ownership | home_ownership_RENT | home_ownership_MORTGAGE | home_ownership_OWN |
| RENT | 1 | 0 | 0 |
| MORTGAGE | 0 | 1 | 0 |
| OWN | 0 | 0 | 1 |
אם לא נעשה המרה זו וננסה להפעיל את המודלים בהשך נקבל הודעת שגיאה.
5. נירמול הנתונים
אחת הפעולות שנהוג לעשות על הנתונים בהרבה מודלים של Machine Learning זה לנרמל אותם ולהביא אותם לאותה סקאלה על ערכים מספריים (לרוב נהוג בין אפס לאחד).
הסיבות לזה הם בעיקר נומריות, והנירמול גורם למודלים רבים להתכנס יותר טוב:
()scaler = StandardScaler
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
6. אימון המודלים ובדיקתם
נתחיל במודל KNN כפי שראינו מקודם, הגדרת המודל:
model = KNeighborsClassifier(n_neighbors=12)
אימון המודל:
model.fit(X_train_scaled, y_train)
בדיקת המודל על קבוצת האימון:
train_accuracy = model.score(X_train_scaled, y_train)
ויותר חשוב מזה, בדיקת המודל על קבוצת הבדיקה:
test_accuracy = model.score(X_test_scaled, y_test)
ובאותו אופן מודל ה Logistic Regression הגדרה, אימון ובדיקות:
model = LogisticRegression(max_iter=1000)
model.fit(X_train_scaled, y_train)
train_accuracy = model.score(X_train_scaled, y_train)
test_accuracy = model.score(X_test_scaled, y_test)
7. תוצאות הבדיקות
תוצאות מודל KNN הינן:
Train Accuracy: 0.708128078817734
Test Accuracy: 0.5133985538068907
דיוק הפרדיקציה (הסתברות החזר ההלוואה) בקבוצת האימון הינה בערך 70% ובקבוצת הבדיקה 51%. ז”א שהמודל אכן למד משהו (כי 70% הצלחה זה לא מקרי) אבל זה לא עוזר לנו בכלום כי על מבקשי הלוואה אחרים שלא השתמשנו בהם באימון הוא כלל לא מצליח (מצליח ב 50% שזה כמו לנחש סתם).
תופעה זו של פער בין הצלחה בין קבוצת האימון לבין קבוצת הבדיקה הינה מאוד נפוצה והיא נקראת overfit. מה שקרה זה שהמודל למד את הנתונים אבל נתפס לתבניות הלא חשובות (לרעש) שהיה בנתונים הספציפיים איתם אימנו את המודל ולראייה כשבוחנים אותו על נתונים אחרים הוא נכשל.
לעומת זאת, תוצאות מודל ה Logistic Regression הינן:
Train Accuracy: 0.7128899835796387
Test Accuracy: 0.7205444491705657
וכאן התוצאות טובות יותר, אומנם גם סביבות ה 70% הצלחה אבל גם על קבוצת האימון וגם על קבוצת הבדיקה, מה שאומר שהמודל גם יחסית מצליח על דוגמאות שלא “ראה” בזמן האימון.
בזאת סיימתי לתת כניסה קלה ופרקטית לעולם ה Machine Learning, אם היה מוצלח ומועיל בעינכם ותרצו עוד כאלו, מוזמנים להגיב בהתאם 😊