
המאוריין: אלון רוזנטל מנהל קבוצת ה DataSciense
רקע
אמובי היא חברת ענק בתחום הפירסום. כדי להבין במה אנו עוסקים צריך להבין את העולם שמאחורי הקלעים בפירסום באינטרנט.
כשכל אחד מאיתנו גולש באיזשהוא אתר, בשבריר השניה שעולה העמוד יש מכרז בין כל המפרסמים שרוצים להציג פרסומות לעמוד הזה ולמשתמש הזה. יש כמובן חשיבות גדולה שהפרסומת תתאים כי הרי לא נרצה לשים פרסומת לסרט קומי חדש בעמוד עם כתבה על פיגוע וגם לא נרצה פרסומת על סכיני גילוח בבלוג שעוסק בהיריון.
לניתוח וקבלת ההחלטה המהירה הזו יש חלק ניכר לענקית אמובי.
באמובי יש צוות חזק שעוסק בעיקר ב NLP. לא מזמן זכינו במקום הראשון בתחרות Sentiment Detection ב WASA2018
כמה אנשי פיתוח ? איך מחולקים ?
קבוצת ה Datasciense של המרכז בארץ מונים 6 מפתחים.
כולם בעלי יכולות תיכנות גבוהות.
שלושה דאטאסיינס, שני מהנדסי Big Data, ואחד גם וגם.
מהם המוצרים בחברה ?
אתאר את עיקרי השירותים שאנו מציעים:
- לספק אנליטיקה על משתמשים (גולשים). שזה אומר למשל פילוג של גיל, מין, מוצא והרגלי גלישה.
- ניתוח (parsing) של דפי אינטרנט לצורך טירגוט (targeting) ובחירה של פרסומות רלוונטיות
- מעקב אחרי קמפיינים שיווקיים ברשת
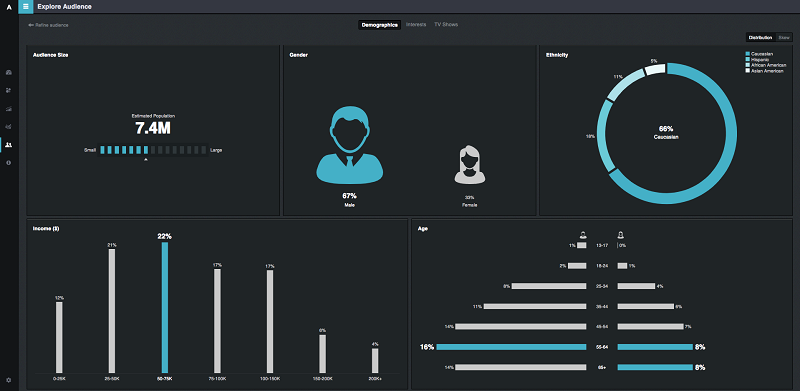
אילו חלקים במוצר מצריכים אלגוריתמיקה ?
כל השירותים שהזכרתי קודם מצריכים אלגוריתמיקה, בעיקר בתחום ה NLP ובייצוג משתמשים.
אחלק את עיקרי הפעילות שלנו לשתים:
תחום ה User Profiling עוסק בהיסטוריה של ארועים והגלישה שיש על המשתמש.
חשוב להבין שעל כל משתמש יש מגוון מקורות מידע: ההתנהגות שלו ברשת, במובייל, ובטלוויזיה.
המטרה לאפשר פילוח של המשתמשים לפי בקשה.
כיוון שיש לנו המון מידע מהרבה מקורות אז אין אחידות במידע. למשל משתמש אחד גולש הרבה במובייל ואין לו טלוויזיה, ולאחר יש גם ווב וגם טלוויזיה אבל קצת מובייל.
מה שאנו רוצים לעשות זה לייצר מידע אחיד לכל המשתמשים, על אף שהגיעו ממקורות שונים. המידע האחיד הזה אמור לייצג תכונות אנושיות (אוניברסליות) ולא תכונות ספציפיות כמו איך הוא גולש בטלוויזיה החכמה שלו. למשל האם הוא מתעניין בכלכלה, אומנות או פוליטיקה (מה שכמובן עוזר לנו לבחור איפה כדאי לפרסם לו)
בעיה זו של יצירת אחידות בייצוג של המשתמשים שלנו מתוך המון נתונים לא אחידים אנו מנסים לפתור באמצעות GAN (ל Embdded) שישלים מידע חסר (כביכול יש מאין). זה נושא שאנחנו עוד חוקרים…
בעיות NLP קלאסיות כמו Sentiment Detection, Topic Detection בכדי להחליט איזו פרסומת תתאים
לאיזה משתמש ולאיזה עמוד.
מה עובד לכם טוב ?
הפתרונות לבעיות ה NLP שלנו השתדרגו משמעותית עם השימוש ב ,Language Modeling שזה קונספט די חדש (מהשנתיים האחרונות).
לוקחים מודל שפה שכבר אומן על לחזות את המילה הבאה על המון טקסט ואז כשבונים מסווג לא מבזבזים זמן אימון מאפס.
מה מאתגר אתכם ?
אנחנו מנסים לשפר את ה State of the art של מודל השפה וזה מאוד מאתגר.
למשל לוקחים את הכי טוב של גוגל Bert ומשלבים עם Evolved Transformer.
בעיות שפתרתם בדרך יצירתית ?
לגבי ה Topic Classification יש דרישה מהתעשייה שהתוצאות יהיו היררכיות, ז”א במבנה של עץ. למשל:
ספורט – > פוטבול -> שחקן מפורסם
רכב – > אופנועים
-> מכוניות מירוץ
-> ג’יפים
…
מה שעשינו זה בנינו ארכיטקטורת רשת ייחודית שזהה למבנה ההיררכי שבתעשייה. זה עבד לנו טוב יותר מאשר ניסיון לחזות כל תת נושא באופן בלתי תלוי.
התבססו על מודל שפה עם וקטורים למאמר וברשת שפיתחנו יש משקלים משותפים לכל פרדיקציה של נושא ושל תת נושא ופונקציות המחיר (Loss functions) גם כן היררכיות.
כך שלמעשה מהקלט הגולמי חוזים את התת נושא.
ממש תפרנו את הרשת לבעיה וזה היה יפה!
ספר על משימת איסוף ה DB אצלכם ? (מי עושה ? מי בודק ? מי מתייג ? מי מנהל ?)
יש לנו כמות לא שגרתית של Data והשימוש בו מאוד תלוי משימה.
יש אינדקס של כל האינטרנט, בין השאר מיליארדי ציוצים מכל השנים האחרונות ושנה אחורה של כל הכתבות הפופולאריות מהרשת כולה. חצי מכוח האדם שלנו עובד בזה והתיוג נעשה ע”י אנליסטים בצוות אחר.
מהם אתגרי העתיד ?
- השלמה ואחידות המידע על היוזרים שהמידעים שלהם מגיע ממקורות שונים מבוסס GAN.
- שיפור מודל השפה כי הכל מבוסס עליו
