
עולם פיתוח האלגוריתמים תמיד כלל מרכיב גדול של ניסוי וטעייה. לפעמים ניסויים מושכלים הנובעים מאינטואיציה ומחשבה ולפעמים ניסיונות שהינם בגדר ניחושים מוחלטים למה גישה כזו או אחרת עשוייה לעבוד.
בשנים האחרונות עם עליית ענף הרשתות נוירונים (בפרט למידה עמוקה) כענף מוביל ברוב הבעיות האלגוריתמיות מרכיב הניסוי וטעייה ה-“לא מושכל” אפילו עלה עוד יותר. הרבה בעיות שפעם נחשבו קשות ולא פתירות ניתנות לפתרון מהיר כתוצאה של שרשרת של ניסוי וטעיה של היפר-פרמטרים ללא שום צורך בידע מתמטי\אלגוריתמי נרחב. לדעתי המהפיכה הזו שינתה את המקצוע ואולי גם מפצלת אותו לתתי מקצועות כמו טכנאים, הנדסאים ומהנדסים.
בכתבה זו אעסוק ברובד היותר טכני אבל מאוד חשוב של ניהול הניסויים והריצות. אעיד על עצמי שבעבר כתבתי קוד שעשה לי סדר בתוצאות הריצות. בכל הרצה הקוד יצר תיקייה חדשה אליה העתיק את הגרפים, העתיק את קוד הריצה עצמו – וזה חשוב כי אחר כך כשמסתכלים על תוצאות ומשווים ללפני שבוע שוכחים מה היה ההבדל בין ריצה לריצה. וזרקתי לאקסל את המאפיינים העיקריים מהריצה שיהיה נוח להשוות עשרות או מאות של ריצות. הסדר הזה מאוד חשוב להשוואה והבנה מה עובד טוב יותר או פחות על הבעיה\DB שלי.
יש הרבה מאוד פלטפורמות שמקלות על ניהול הריצות הזה. לא מכיר את כולם ולא יכול לעשות השוואה, אבל אספר על כלי מסויים שנקרא Neptune שנקלעתי אליו אחרי שנפגשתי עם אחד מיוצריו בכנס. מסתבר שהחברה האלו הם אלו שזכו מקום ראשון באחת התחרויות המפורסמות שהיו ב Kaggle, זיהוי לווייתנים (ראו פה הסבר על הפתרון שלהם). הוא סיפר שהצוות שלהם אימן מודל משולב (ensemble model) שנתן תוצאה הכי טובה. ואז כשניסו לשחזר את הריצה הם לא היצליחו כי לא שמרו את ההיפר-פרמטרים של הריצה המוצלחת. למזלם אחרי עוד קצת עבודת ניסוי וטעיה הם השתמשו באותוensemble model והיצליחו להגיע לתוצאה שגם היא ניצחה בתחרות. זה הרגע שהוביל אותם לבנות כלי שיעשה סדר בכל הריצות וזה בהתחלה שימש את החברה שלהם בלבד ובהמשך הפכו אותו למוצר נגיש לכולם.
מהו Neptune
פלטפורמה וובית דומה מאוד ל GitHub המאפשרת שיתוף ושמירה של ריצות על כל הנתונים שהיא מייצרת: הקוד עצמו, הגרפים, התמונות, הפלטים, ההערות, התיוגים, וכו’. כיוון שהכל מרוכז במקום אחד ובעל מבנה אחיד מאוד נוח להשוות רעיונות שנוסו בין חברי צוות שונים על אותה בעיה. השימוש חינמי ליחידים, לצוותים אמורים לשלם )שוב, די דומה ל GitHub).
כמובן שהכל מגובה ומאובטח.
איך משתמשים ?
ראשית נרשמים כאן ומקבליםtoken אישי, מגדירים את ה token כמשתנה מערכת:
NEPTUNE_API_TOKEN=”…”
ואז הגישה יכולה להיות מ R או פייתון, אדגים עם פייתון.
מתקינים:
pip install neptune-client
ואז מכניסים לקוד שלכם את שלושת שורות הקוד הבאות:

כמובן שלא חייבים לשים tags, description ולהעלות את הקוד הנוכחי אבל זה מאוד מומלץ כדי שכשיצטברו לנו מאות ריצות נוכל בקלות לעשות סדר מה היבדיל את הריצות היותר מוצלחות מהפחות.
לאחר יצירת הניסוי בכל שלב בקוד שלכם תוכלו לשלוח כל דבר לשרת שיישמר עם הריצה הזו.
לצורך כך הוסיפו שורות שכאלו:
neptune.send_metric(‘Variable I want to store’,var1)
neptune.send_image(‘Image I want to see while training’,img1)
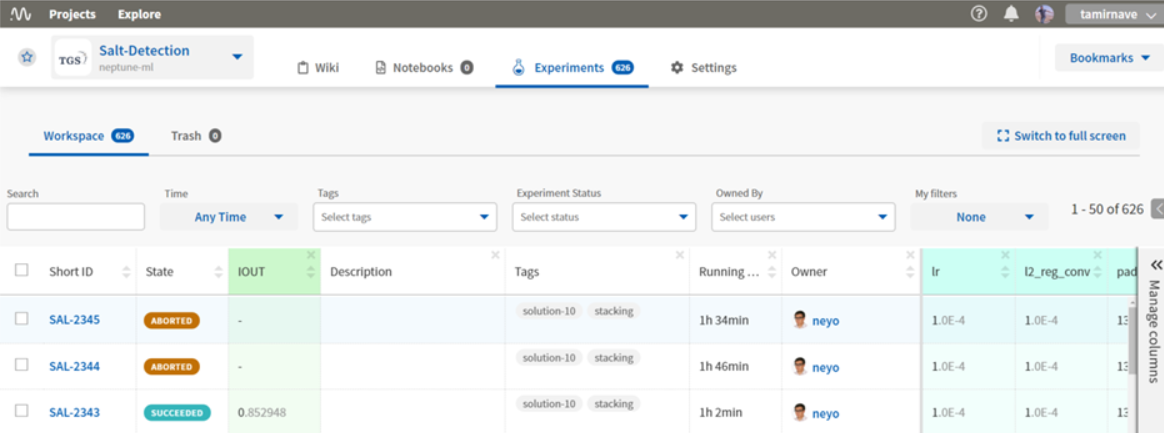
כשהקוד ירוץ תתווסף שורה לרשימת ה experiments ב dashboard של Neptune עם כל המאפיינים:
התגיות מועילות כי בעוד חודש שנשכח למשל שבדקנו איך dropout הישפיע על הביצועים נחפש את כל הריצות עם התגית הזו, עוד שנה שננסה להיזכר מה הייתה הריצה הכי טובה עם מודל ה Xception למשל נחפש תגיות (שאנחנו כתבנו בשורת ה neptune.create_experiment עם המילים best, xception)
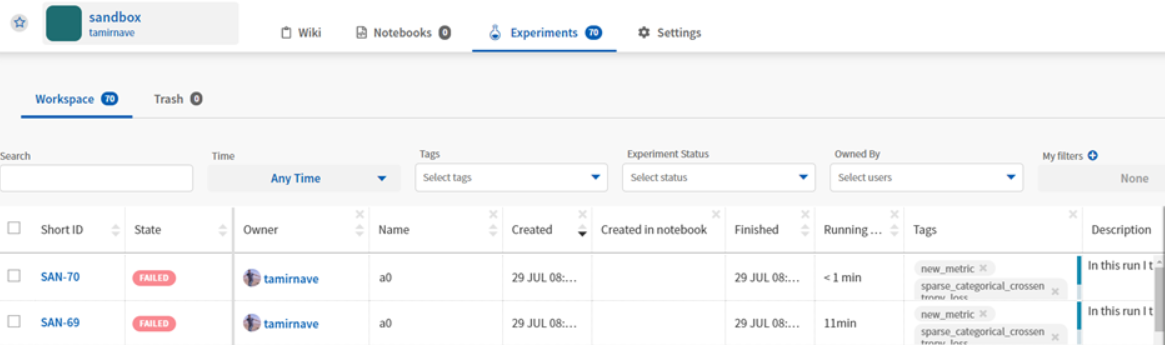
גישה לתמונות ולגרפים
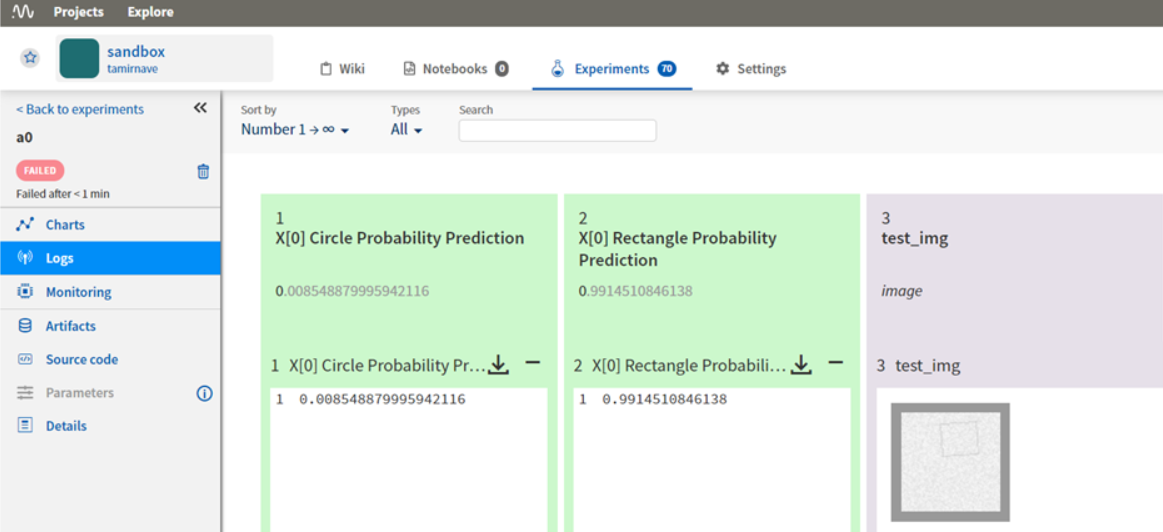
כדי לראות את נתוני הריצה נלחץ על ה experiment הרצוי ושם כל אלמנט ששלחנו יוצג (משתנים\תמונות\גרפים וכו’). לחיצה על כל אחד תציג אותו:
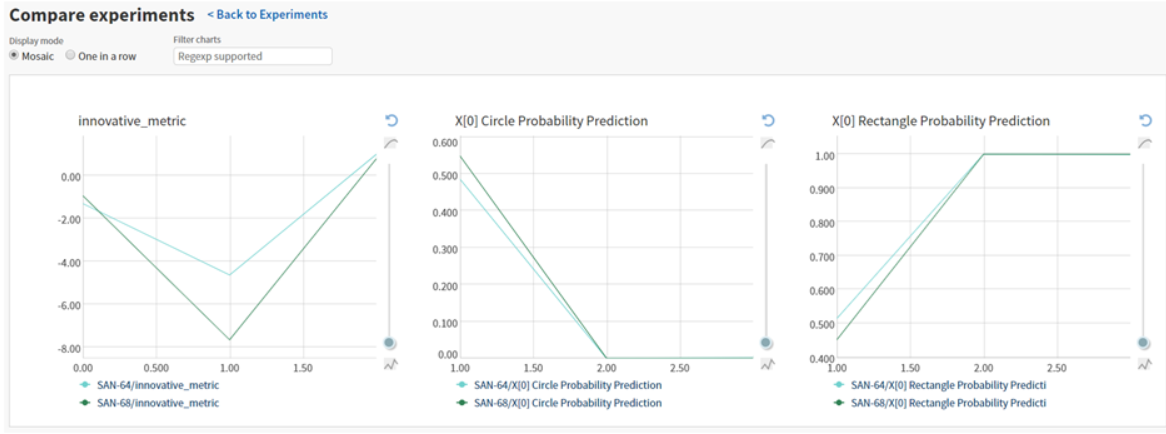
השוואות בין ריצות
כשנרצה להשוות בין משתנים כלשהם מריצות שונות נסמן את הריצות הרצויות מהרשימה ונלחץ על compare.
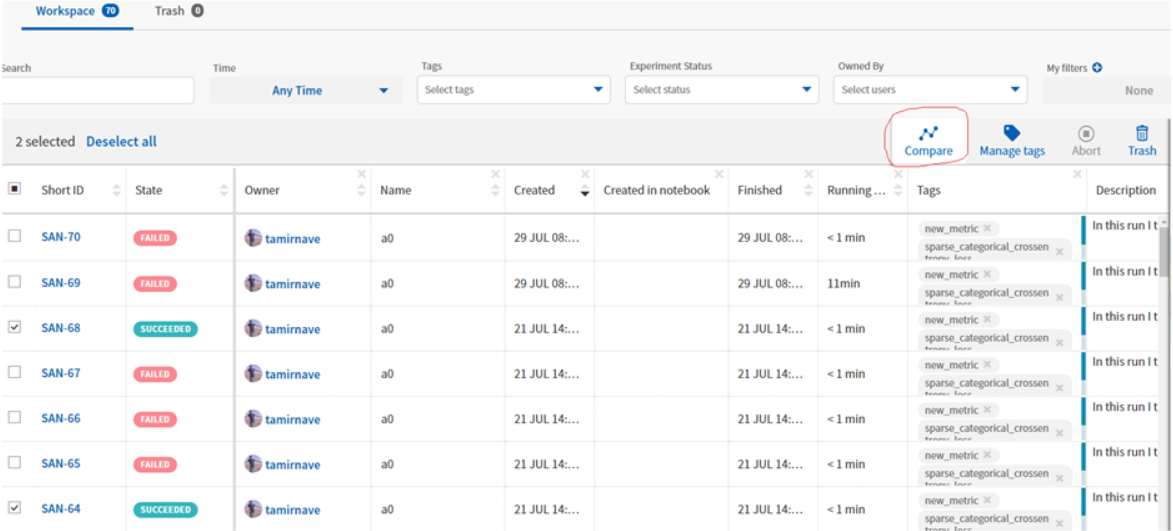
מה שנקבל זה גרפים של המשתנים ששלחנו וכל ריצה תהיה בצבע אחר:
לסיכום
מרכיב חשוב בפיתוח אלגוריתמים הוא ניסוי וטעיה. ככל שנהיה מסודרים בזה כך נצליח יותר מהר להגיע אל מטרות הפיתוח שלנו. הצגתי כלי איתו אני עובד Neptune, יש עוד מגוון כלים עליהם אני מזמין אתכם לכתוב גם. אז אנא מכם רישמו בתגובות למטה מה הדרך שלכם או מה הכלי שלכם לעשות סדר בג’ונגל התוצאות…
