
כאשר בונים רשת נוירונים אחת ההחלטות החשובות שצריך לקבל היא באילו פונקציות אקטיבציה להשתמש בשכבות הפנימיות ובשכבת הפלט. בכתבה זו נסקור את האופציות השונות.
מדוע משתמשים בפונקציות אקטיבציה לא לינאריות?
מסתבר שבכדי שהרשת תוכל ללמוד פונקציות מענינות, אנו נצטרך להשתמש בפונקציות אקטיבציה לא לינאריות. זאת מפני שהרכבה של שתי פונקציות לינאריות נותנת פונקציה לינארית.
נסתכל לדוגמה על הרשת הבאה, ונראה מה יקרה אם נשתמש בפונקציית הזהות בתור פונקציית האקטיבציה.
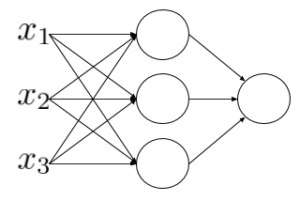
נשתמש בפונקציית הזהות בתור פונקציית אקטיבציה:
נחשב את האקטיבציה של השכבה הבאה:
קיבלנו שמוצא הרשת מתארת פונקציה לינארית. למעשה לא משנה כמה שכבות יש לנו ברשת, אם לא מוסיפים אי-לינאריות לרשת, הרשת תוכל ללמוד רק פונקציה לינארית, לא יועילו. שימוש בפונקציות לא לינאריות מאפשר לנו ללמוד יחסים מורכבים יותר.
פונקציית האקטיבציה הראשונה שהייתה בשימוש ברשתות הייתה סיגמואיד
סיגמואיד:

הסיגמואיד מכווץ את המספרים לטווח של [0,1] . הוא היה פופולרי בעבר בשל הדמיון לפעולת אקטיבציה במוח האנושי. לפונקציית סיגמואיד יש כמה חסרונות בולטים בתור פונקציית אקטיבציה.
Saturation (רוויה)- הרוויה הורגת את הגרדיאנט. כאשר השיפוע מתיישר הגרדיאנט שואף ל-0 ולכן פעפוע לאחור לא יוכל לעדכן את המשקלים.
לא ממורכז סביב ה0– אם נסתכל על הגרדיאנט של וקטור המשקלים w, כל המשקלים בו יהיו בעלי אותו סימן חיוביים או שליליים. לדוגמא עבור w ממימד 2
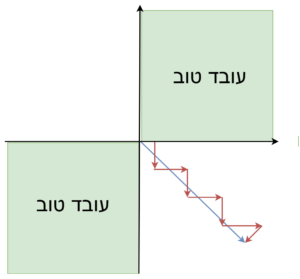
במידה ונרצה להתקדם בכיוון הרביע הרביעי (x חיובי y שלילי) כפי שאפשר לראות בשרטוט לעיל, נצטרך ללכת בזיגזגים, כי בכל צעד או שכל הנגזרות החלקיות חיוביות או שכולן שליליות. מאט את קצב ההתכנסות.
חישוב האקספוננט לוקח זמן רב
כדי לפתור את הבעייה שנוצרה מכך שסיגמואיד לא ממורכז סביב ה-0 עברו להשתמש בפונקציית tanh.
(טנגנס היפרבולי) tanh

tanh מתנהגת כמו סיגמואיד שעבר הזזה והכפלה בקבוע. גרסה אחרת של tanh נראית כך: . tanh ממורכזת סביב ה-0 מכווץ את המספרים לטווח של [1,1-].
Saturation (רוויה)- בדומה לסיגמואיד tanh סובל מבעייה של דעיכת גרדיאנטים (vanishing gradient) בגלל רוויה.
חישוב tanh לוקח זמן רב
כיום tanh שימושי בעיקר עבור רשתות rnn.
ReLU

AlexNet הייתה הרשת הראשונה שהחליפה את פונקציית האקטיבציה ל-ReLU, וגרמה לרשת להתכנס פי 6 יותר מהר.
ReLU מהיר לחישוב ביחס לסיגמואיד ו-tanh.
כאשר x חיובי אין סטורציה (רוויה), מה שעוזר להתכנסות מהירה. אבל כאשר יש משקל שלילי הגרדיאנט מת, וכך גם הנוירונים התלויים בו כי הם מפסיקים להתעדכן.
היו ניסיונות ליצור פונקציות שלא יגיעו לרווייה והמציאו פונקציות אקטיבציה שהנגזרת שלהן לא מתאפסת כדי למנוע מנוירונים למות, כלומר שיפסיקו להתעדכן בעקבות התאפסות הגרדיאנט.
Leaky ReLU
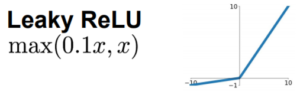
מאוד דומה ל-relu אבל הגרדיאנט שלו לא מתאפס כאשר x<0. מבחינה פרקטית, אין קונצנזוס שהוא נותן תוצאות טובות יותר, יש מאמרים לכאן ולשם.
Maxout
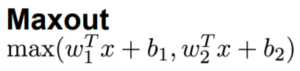
לא נכנסת לסטורציה אבל מכפילה את מספר המשקלים ברשת, במקום w יש לנו עכשיו w1 וw2. מסיבה זו היא לא פרקטית
ELU
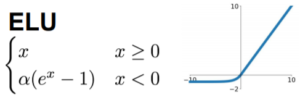
חישוב אקספוננט לוקח זמן רב.
ELU ו-MaxOut נמצאים בשימוש רק לעיתים רחוקות, מפני שאין עדיות חד משמעיות שהן עובדות טוב יותר מReLU והן יותר יקרות מבחינה חישובית. נראה שאין עדויות חד משמעיות לכך שפונקציות שלא מגיעת לרוויה כמו ELU ,MaxOut או Leaky ReLU משפרות תוצאות, אז נשאלת השאלה איך בכל זאת נוכל למנוע מנוירונים למות?
מה אפשר לעשות כדי למנוע מנוירונים ברשת למות ?
זה סטנדרטי שחלק מהנוירונים ברשת מתים. הדבר העיקרי שעוזר הוא לבחור learning rate (גודל הצעד בכיוון הגרדיאנט) בצורה נבונה.
בחירת learning rate גבוה, עלול לגרום לנוירונים למות. שינוי גדול בערך המשקולות עלול לשנות באופן מהותי את הערכים שנכנסים אל פונקציית האקטיבציה ולהוביל אותנו לאיזור הרוויה. בנוסף learning rate גבוה עלול לגרום לנו ל”דלג” (overshoot) מעל הפתרון הנכון.
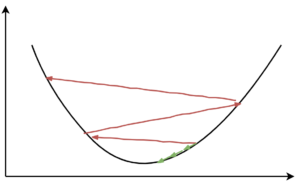
עם זאת בחירת learning rate נמוך מדי יאט את קצב ההתכנסות.
דרכים נוספות כדי למנוע מנוירונים למות הן pruning או dropout, ו-batch normalization.
מתכוננים לראיונות עבודה? ענו על השאלות הבאות בנושא:
- מדוע אנחנו זקוקים לפונקציות אקטיבציה?
- כתוב את פונקציית סיגמואיד ושרטט אותה?
- מה הנגזרת של פונקציית סיגמואיד?
- מה הבעיות בשימוש בפונקציית סיגמואיד בתור פונקציית אקטיבציה?
- מה גורם לתופעת ה vanishing gradient ברשתות, ובאילו דרכים אפשר להתמודד איתה?
כתבו את תשובותיכם בתגובות וקבלו מאיתנו פידבק. תפגיזו בראיונות!
מקורות:
046003, Spring 2019 טכניון
cs231n_2019 7 מצגת
Activation Functions (C1W3L06)
Why Non-linear Activation Functions (C1W3L07)
Lecture 0204 Gradient descent in practice II: Learning rate
[contact-form][contact-field label=”Name” type=”name” required=”true” /][contact-field label=”Email” type=”email” required=”true” /][contact-field label=”Website” type=”url” /][contact-field label=”Message” type=”textarea” /][/contact-form]
