
הדאטה הנפוץ ביותר בתעשייה הינו דאטה טבלאי, נתונים טבלאיים הינם מובנים וקל יותר להתמודד איתם כאשר מאמנים מודלים, עם זאת כשזה מגיע לייצור נתונים סינתטתיים מסוג זה, כדי לשפר ביצועים של מודלים, הדבר מתחיל להסתבך.
אמנם CTGAN אינו מושלם ולא מצליח ללכוד מידע משותף בין המשתנים, אך הוא הבסיס של ארכיטקטורות למידת מכונה רבות אשר מהוות את ה-SOTA של תחום יצירת נתונים טבלאיים.
דאטה טבלאי
סוגי דאטה טבלאי- נתונים טבלאיים יכולים להיות מספריים (רציפים כמו גובה או בדידים כמו גיל), או קטגוריים (עם סדר כמו יום בשבוע או נומינליים (ללא סדר) כמו מין).
לרוב מתייחסים לנתונים קטגוריים ובדידים באותו אופן, מכיוון שטרם השימוש במשתנים קטגוריים במודלים השונים מבצעים המרה שלהם למספרים.
הגדרת הבעיה- נניח דאטה טבלאי T שמכיל Nd עמודות בדידות ו-Nc עמודות רציפות, המטרה הינה לאמן מחולל G ללמוד לייצר דאטה טבלאי סינתטי מ-T שיקרא Tsyn.
כדי להעריך את ביצועי המחולל מפצלים את T לאימון ומבחן, ובוחנים שני היבטים:
- התאמת הנתונים ב- Tsyn להתפלגות הנתונים ב- Ttrain
- השוואת מודל סיווג/רגרסיה מאומן על Tsyn עם מודל מאומן על Ttrain, מבחינת ביצועים על Ttest
GAN–Generative Adversarial Network
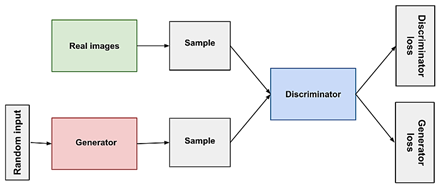
מדובר במודל שבא לפתור בעיית למידה מונחית בה יש לנו דאטה של תמונות אמיתיות ונרצה להגדיל אותו, ועושה זאת ע”י למידת ייצור דגימות.
המודל מורכב משתי רשתות נוירוניות, המחולל והמאבחן, המחולל מייצר נתונים חדשים בעוד שהמאבחן מנסה להבדיל בין נתונים אמיתיים למזויפים, לרשתות פונקציות loss מנוגדות, המאבחן מנסה למקסם את דיוק הסיווג שלו, והמחולל מנסה לרמות את המאבחן, בסוף האימון המחולל אמור להצליח לייצר תמונות שנראות כמו התמונות האמיתיות, כך שאפילו בני אדם עשויים לחשוב שהן אמיתיות.
התאמות שנעשות ב-CTGAN
השימוש ב-GAN רגיל לייצור דאטה טבלאי יוצר שתי בעיות שההתאמות ב-CTGAN באות לפתור:
1. נרמול מייצג של דאטה רציף– נתונים דיסקרטיים קלים לייצוג מכיוון שניתן להשתמש בוקטור אחד חם, אך בנתונים רציפים קשה לבטא את כל המידע על ההתפלגות ע”י שימוש בערך המשתנה בלבד, לכן הפתרון המוצע עבור עמודות רציפות הינו נרמול ספציפי לשכיח, אשר ממיר משתנה רציף לוקטור המתאר את המידע על ההתפלגות.
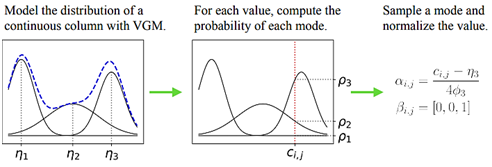
לכל משתנה רציף תחילה מתאימים VGM (variational Gaussian mixture model), GM רגיל מנסה למצוא את k הגאוסיאנים שמייצגים הכי טוב את הנתונים דרך שימוש ב-EM, לעומת זאת VGM-ים יכולים להחליט מהו ה-k הכי מתאים לנתונים דרך סף משקולות.
לאחר שנמצאו k (בדוגמה מעלה k=3) ההתפלגויות שממדלות הכי טוב את המשתנה הרציף (בדוגמה מעלה עמודה i), מעריכים את ההסתברויות (בדוגמה מעלה ρ1,ρ2,ρ3) להשתייכות הדגימה (בדוגמה מעלה j) לכל אחת מההתפלגויות, מהן דוגמים את ההתפלגות הנבחרת (מסומנת ב- β), ואז מייצגים את ערך הדגימה בתוך ההתפלגות שלה (כמה היא חשובה בתוך הגאוסיאן שלה) ע״י שימוש ב-α , כאשר η הינו השכיח ו-φ הינה סטיית התקן של ההתפלגות.
כעת עבור כל דגימה המודל יקבל במקום הערכים הרציפים,שרשור של α ו-β של כל העמודות הרציפות, עם וקטורי האחד חם של העמודות הבדידות.
2. דגימה הוגנת של משתנים בדידים– באימון GAN רעש הקלט מיוצר מהתפלגות פריורית (לרוב גאוסיאנית מרובת משתנים), דגימה זו עבור משתנים בדידים עשויה להחמיץ מידע על התפלגותם ולשמר את חוסר האיזון בדאטה, נרצה לבצע דגימה מחדש בדרך שמאפשרת דגימה שווה בין ערכים דיסקרטיים שונים בזמן האימון, ושחזור ההתפלגות האמיתית בזמן המבחן.
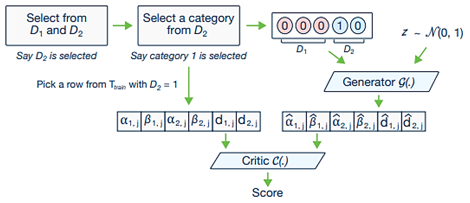
הפתרון המוצע מורכב מ-3 אלמנטי מפתח:
a. וקטור מותנה– וקטור אשר מכיל מידע על המשתנים הבדידים, ומשתמשים בו כדי לכפות על המחולל לייצר דגימות משתנים בדידים עם התפלגות דומה לנתוני האימון.
הוקטור מכיל שרשור של כל וקטורי אחד חם של העמודות הבדידות, כך שכל הערכים הינם 0 מלבד קטגוריה אחת מאחת העמודות הבדידות, והוא מאלץ את המחולל לייצר דגימה מקטגוריה נבחרת זו.
b. הפסד המחולל– כדי לוודא שהאילוץ אכן מתקיים מענישים את פונקציית ההפסד של המחולל ע”י הוספת CE בין החלק של העמודה בה יש 1 בוקטור המותנה, לחלק של אותה עמודה בדגימה המיוצרת.
c. אימון לפי דגימה– דוגם את התנאים לפיהם נוצר הוקטור המותנה, כך שההתפלגויות הנוצרות ע”י המחולל יתאימו להתפלגויות המשתנים הבדידים בנתוני האימון.
אימון לפי דגימה מתבצע כך:
- תחילה עמודה בדידה נבחרת אקראית
- מעמודה זו נבחרת קטגוריה על בסיס פונקציית מסת הסתברות הבנויה מתדירות ההתרחשות של כל קטגוריה באותה עמודה
- התנאי עובר טרנספורמציה לוקטור המותנה ומהווה קלט למחולל
קוד
חבילת פייתון רלוונטית והסבר על אופן השימוש בה
קישורים רלוונטיים
