בכתבה זו סיכמתי את המאמר: “ Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing” שפורסם ב 16.09.21 ב arxiv. זהו מאמר מומלץ למתעניינים במודלי שפה עבור דומיינים שונים, בעיקר למתמקדים בדומיין הרפואי. המאמר כתוב בצורה ברורה ודורש היכרות בסיסית עם מודלי שפה ו-BERT. למי שרוצה להכיר יותר את המושגים הבסיסים שמוזכרים מוזמן לקרוא עוד בקישורים למטה.
מבוא
בעיבוד שפה טבעית (NLP) אימון רשתות נוירונים גדולות מראש על טקסט לא מתויג (משימת self-supervised) הוכח כאסטרטגיה מוצלחת בהעברת לימוד, דוגמה טובה לכך הינו מודל BERT שהפך לאבן בניין באימון מודלים למשימות NLP.
אך מודל BERT המקורי אומן על טקסטים מהאינטרנט כמו ויקיפדיה וספרים, ולצורך התאמתו לדומיינים אחרים, כמו הדומיין הרפואי, בד”כ ממשיכים לאמן אותו על אותן משימות self-supervised עם טקסט מהדומיין המסוים.
במאמר מראים שאימון עם טקסט מהדומיין המסוים מלכתחילה עדיף על פני אימון עם טקסט כללי ולאחריו עם טקסט מהדומיין המסוים, לצורך בחינת ההשערה פורסם גם דאטה סט שנקרא BLURB.
BERT
אוצר מילים– כדי להימנע מהבעיה בה מילים לא מופיעות באוצר המילים, ביצירת אוצר המילים לטוקנזיציה משתמשים ביחידות תתי מילים. במאמר משתמשים באלגוריתם WordPiece שהוא וריאציה של Byte-Pair Encoding (BPE) (אלגוריתם שמנסה בצורה חמדנית למצוא תתי מילים שיכולות ליצור את כל המילים, ומגדיל את אוצר המילים ע״י שרשור תתי המילים עד להגעה למספר מילים שהוגדר מראש), רק שבבחירת תתי המילים לשרשר מתבסס על מודל unigram ולא על תדירות.
לגבי גודל האותיות ניתן לשמר אותיות גדולות או להפוך את כולן לקטנות.
ארכיטקטורה– מבוססת transformer שהוא מנגנון self-attention מרובה ראשים ושכבות, ארכיטקטורה עדיפה על LSTM מכיוון שמקבילית ותופסת תלויות ארוכות טווח.
רצף טוקני הקלט מעובד תחילה ע”י מקודד לשוני שסוכם איבר איבר את ה-embedding-ים של הטוקן של המיקום ושל הקטע (לאיזה קטע בטקסט שייך הטוקן), וזה מועבר למספר שכבות transformer, בכל שכבת transformer נוצר ייצוג הקשרי לכל טוקן, ע”י סכימת טרנספורמציה לא לינארית של ייצוגי כל הטוקנים בשכבה הקודמת ממושקלים לפי ה-attention, שמחושב ע”י שימוש בייצוגי הטוקנים בשכבה הקודמת כשאילתה (query). השכבה האחרונה פולטת ייצוג הקשרי לכל הטוקנים שמשלב מידע מכל הטקסט.
פיקוח עצמי (self-supervision)– החידוש ב-BERT הוא השימוש במודל שפה ממוסך, שמחליף תת קבוצה של טוקנים באופן אקראי בטוקן [mask] ומבקש ממודל השפה לחזות אותם, לעומת מודלים מסורתיים שמנבאים את הטוקן הבא על סמך הקודמים. פונקציית המטרה היא CE בין הטוקנים הנחזים למקוריים. ב-BERT ו-RoBERTa נבחרים 15% מהטוקנים, מתוכם 80% ממוסכים 10% לא משתנים ו-10% מוחלפים בטוקן אקראי מאוצר המילים. (גישה נוספת היא להגדיל את שיעור המיסוך בהדרגה לאורך האפוקים מ-5% ל-25% מה שהופך את האימון ליציב יותר).
ב-BERT המקורי קל לחזות את הטוקנים הממוסכים מכיוון שלרוב טוקן מייצג תתי מילה וידיעת שאר המילה מקלה, במאמר משתמשים במיסוך של מילים שלמות אשר מאלץ את המודל ללכוד יותר תלויות הקשריות. בנוסף ב-BERT משתמשים גם במשימת חיזוי האם משפט אחד עוקב לשני בהינתן זוג משפטים (התועלת של משימה זו מוטלת בספק).
מודל שפה ביו-רפואי מאומן מראש (ביו-רפואה משמש כדוגמה לדומיין מסוים)
אינטואיטיבית שימוש בטקסט מהדומיין באימון מראש אמור לעזור ליישומים בדומיין זה, ואכן עבודה קודמת הראתה שאימון מראש עם PubMed הוביל לביצועים טובים יותר. השאלה היא האם האימון מראש צריך לכלול טקסט מדומיינים אחרים בנוסף (ההנחה הרווחת היא שתמיד ניתן להשיג תועלת מטקסט נוסף גם אם הוא מחוץ לדומיין), למעשה אף אחד ממודלי BERT הביו-רפואיים הקודמים לא אומנו מראש רק על טקסט ביו-רפואי.
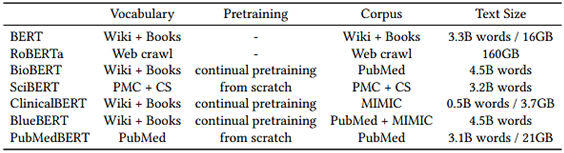
אימון מראש מעורבב דומיינים– הגישה הסטנדרטית לאימון מראש של BERT ביו-רפואי אשר נקראת אימון מתמשך (כמו ב-BioBERT) אשר מבצעת אימון מראש עם דומיין כללי (BERT המקורי – לכן נוח), וממשיכה את האימון על שתי המשימות (פיקוח עצמי) עם שימוש בטקסט ביו-רפואי (במקרה של BioBERT על תקצירי PubMed וכתבות מלאות של PubMed, ובמקרה של BlueBERT על PubMed והערות קליניות לא מזוהות מ-MIMIC-III).
מודל נוסף הוא SciBERT אשר מתאמן מאפס על טקסט ביו-רפואי וטקסט מדעי המחשב (שהוא מחוץ לדומיין).
אימון מראש מאפס לדומיין מסוים– הגישה המעורבת הגיונית אם לדומיין המסוים יש מעט טקסט, אך זה לא המקרה בביו-רפואה, ב-PubMed יש יותר מ-30 מיליון תקצירים ומתווספים יותר ממיליון כל שנה.
יתרון של אימון מראש לדומיין מסוים הוא שאוצר המילים בתוך הדומיין, כשהטוקנזיציה מבוססת על אוצר מילים כללי כמו ב-BERT הרבה מילים מהדומיין המסוים עשויות להתפצל באופן לא רלוונטי, למשל המחלה lymphoma תפוצל לטוקנים l-ym-ph-oma. יתרון נוסף הוא שהמודל לא מוותר על אופטימיזציה של דאטה מהדומיין על חשבון אופטימיזציות אחרות.
BLURB
בעבודות קודמות על אימון מראש ביו-רפואי השתמשו במשימות ודאטה סטים שונים כדי להעריך ביצועים, מה שהקשה להשוות ולהעריך את ההשפעה של מודלי שפה מאומנים מראש. לכן יצרו את BLURB שמתמקד ביישומי NLP ביו-רפואיים מבוססי PubMed, תוך תיעדוף בחירה של דאטה סטים ששימשו בעבודות קודמות על אימון מראש ביו-רפואי כדי שתהיה היכולת להשוות. ציון מסכם של מודל על BLURB יהיה ממוצע הציונים על סוגי המשימות הבאות: זיהוי ישות שם (NER), חילוץ מידע רפואי מבוסס ראיות (PICO), חילוץ קשרים, דמיון משפטים, סיווג מסמכים, מענה על שאלות (QA).
המאמר מפרט לכל משימה על הדאטה סטים השונים שיש ב-BLURB, ועל אופן ההערכת הביצועים במשימה.
כוונון עדין ספציפי משימה
מודלי שפה מאומנים מראש מספקים בסיס לאימון מודלים ספציפיים למשימה, בהינתן רצף טוקנים כקלט הם מייצרים ייצוג הקשרי ולאחר מכן הוא מועבר לשכבות של מודלים ספציפיים למשימה.
בעבודות קודמות לרוב משתמשים בשכבות ובשיטות כוונון עדין (fine tuning) שונות, מה שמקשה על הבנת ההשפעה של המודל המאומן מראש על הביצועים. כדי להשוות מודלים מאומנים מראש, במאמר מקבעים את המודל הספציפי למשימה ומשנים רק את האימון מראש, לאחר מכן מתחילים מאותו BERT ובודקים גם את ההשפעה של מודלים ספציפיים למשימה.
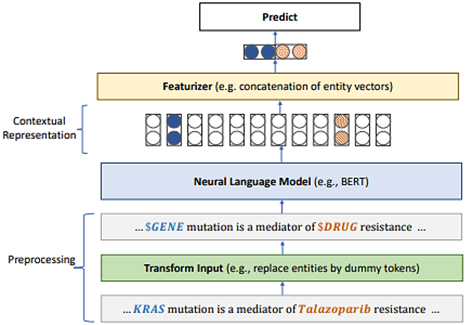
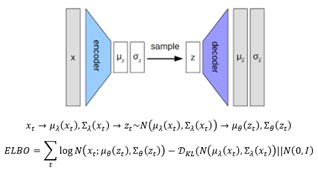
ארכיטקטורה כללית עבור מודלי כוונון עדין של מודלי שפה– כפי שרואים באיור מטה תחילה מעובד הקלט בהתאם למשימה, אח”כ מתבצע תהליך טוקניזציה ע”י שימוש באוצר המילים של המודל, והתוצאה נכנסת למודל. לאחר מכן הייצוגים ההקשריים עוברים עיבוד ומועברים למודול החיזוי שמייצר פלט סופי.
כדי להקל על ההשוואה במאמר מבצעים את אותו כוונון עדין לכל BERT וכל משימה, משתמשים ב-Loss CE למשימות סיווג וב-MSE למשימות לרגרסיה, מבצעים חיפוש הייפרפרמטרים ע”י שימוש בסט ה-dev עם מטריקות מתאימות למשימה, ובדומה לעבודות קודמות עושים כוונון עדין גם לראש וגם למודל הבסיסי.
פרמול ובחירת מידול לבעיה ספציפית למשימה– משימות ה-NLP השונות שבמאמר יכולות להיות משימות סיווג פר טוקן, סיווג רצף, ורגרסיה פר רצף, והמידול שלהן יכול להשתנות בשני היבטים ייצוג המופע (החלק הירוק באיור מעלה) ושכבת החיזוי (החלק האחרון באיור מעלה) במאמר מופיע פירוט על המידולים השונים בהם משתמשים לכל משימה.
הגדרות ניסוייות
במאמר מפרטים על אופן אימון מודל שפה ביו-רפואי מראש מאפס (PubMedBERT) כפי שהכותבים ביצעו, מפורט אוצר המילים והתאמות שלו, האופטימיזציה (קצב למידה, מספר צעדים, גודל batch), משך האימון, המיסוך אותו ביצעו, המודלים אליהם משווים, אופן ביצוע הכוונון העדין (אופטימיזציה- גודל צעד, dropout), אופן כוונון הייפרפרמטרים, וחישוב הביצועים.
תוצאות
אימון לדומיין ספציפי מראש מול אימון מעורבב דומיינים מראש–
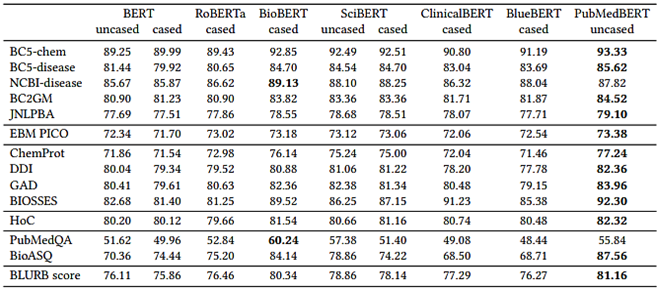
בטבלה ניתן לראות ש-PubMedBERT הכי טוב בפער משמעותי ובעקביות על משימות NLP ביו-רפואיות, בעיקר בהשוואה למודלים שאומנו על דאטה מחוץ לדומיין, מלבד במשימת מענה על שאלות על דאטה סט PubMedQA מכיוון שהדאטה סט קטן והשונות בין תוצאות אתחולים שונים גדולה.
השפעה של שיטות אימון מראש שונות–
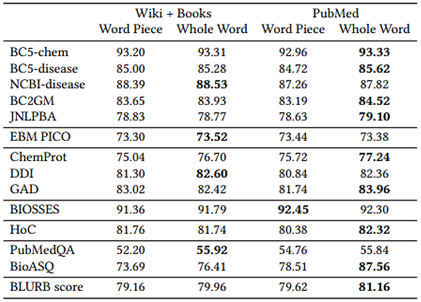
בטבלה מוצגות התוצאות שמראות את ההשפעה של אוצר המילים ומיסוך מילים שלמות. ניתן לראות שאימון מתמשך עם אוצר מילים של BERT (ולאחר מכן של PubMed) פחות טוב מאימון עם אוצר מילים בתוך הדומיין – אוצר מילים מתוך הדומיין גורם לכך שהקלט של המשימות קצר יותר (עקב תהליך טוקניזציה מתאים יותר) מה שמקל על האימון. בנוסף שימוש במיסוך מילים שלמות מוביל לשיפור באופן עקבי ללא תלות באוצר המילים.
תוצאה נוספת מראה שאימון מראש על טקסט כללי לא מספק שום תועלת גם אם משתמשים בנוסף בטקסט מהדומיין.
בנוסף אימון מראש עם תקצירי PubMed בלבד הביא לביצועים טובים יותר מאשר עם מאמרים מלאים מ-PubMed בנוסף לתקצירים (על אף שכמות הטקסט גדלה משמעותית), אך בחלק מהמשימות אימון ארוך יותר שיפר את הביצועים.
משערים שהסיבות לכך הן:
1) מאמרים מלאים מכילים יותר רעש מתקצירים, ומכיוון שרוב המשימות מבוססות על תקצירים טקסטים מלאים עשויים להיות מעט מחוץ לדומיין.
2) גם אם הטקסטים המלאים עשויים להיות מועילים הכללתם דורשת יותר מחזורי אימון.
השפעה של מידולים שונים עבור כוונון עדין ספציפי למשימה– בתוצאות מעלה קיבעו את שיטות הכוונון העדין, עתה מקבעים את המודל המאומן מראש ל-PubMedBert (עם מיסוך מלא ושימוש בתקצירים בלבד). השפעת מודל החיזוי:
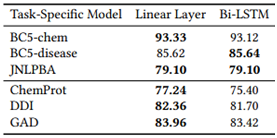
ניתן לראות שעבור משימות זיהוי ישות שם וחילוץ יחסים שכבה לינארית מספיק טובה (מכיוון ששימוש ב-BERT כבר לוכד תלויות לא לינאריות לאורך הטקסט) ושימוש ב-Bi-LSTM לא מוביל לשיפור.
השפעת סכמת התיוג במשימת NER:
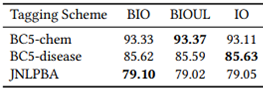
עבור שיטות כמו CRF סכמת תיוג שמבדילה בין מיקום המילה בתוך הישות (BIO או BIOUL) עשויה להיות יתרון, אך עבור מודלי BERT, כפי שניתן גם לראות בטבלה מעלה, התועלת של סכמת תיוג מורכבת פוחתת וההבדל מינורי.
השפעת דמיפיקציה של ישויות וקידוד קשרים:
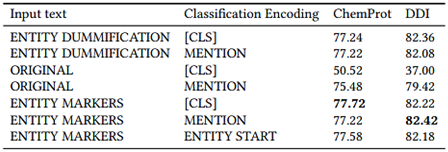
לסימון ישויות 3 אפשרויות-
1) דמפיקציה של ישויות- החלפת הישויות שבקשר בתוויות ישויות השם שלהן
2) טקסט מקורי
3) סימוני ישויות- הוספת טוקן התחלה וסוף לפני ואחרי כל ישות בקשר
לאופן קידוד היחסים 3 אפשרויות-
1) הייצוג ההקשרי של טוקן CLS בתחילת הטקסט
2) שרשור הייצוגים של הישויות בקשר
3) במקרה של הוספת טוקני התחלה וסוף- שרשור ייצוגי טוקני ההתחלה של הישויות
ניתן לראות שהשימוש בטקסט המקורי עשוי להוביל להתאמה יתר על המידה משמעותית, ויחד עם טוקן CLS הוא הגרוע ביותר (קשה לדעת לאילו ישויות מתייחס היחס). שימוש בטוקני התחלה וסוף מוביל לתוצאות הכי טובות, מכיוון שכנראה מונע התאמה יתר על המידה תוך שמירה על מידע שימושי על הישויות.
סיכום
המאמר קורא תיגר על ההנחה הרווחת באימון מראש של מודלי שפה, ומראה שאימון מראש מאפס ספציפי לדומיין יכול לשפר משמעותית אימון מראש מעורבב דומיינים (כמו אימון מראש מתמשך ממודל של שפת דומיין כללי), מה שמוביל לתוצאות SOTA חדשות עבור מגוון רחב של יישומי NLP ביו-רפואיים.
בנוסף יצרו את BLURB, בנצ’מרק מקיף ל-NLP ביו-רפואי הכולל מערך מגוון של משימות, שמאפשר השוואה בין מודלים.
קישורים

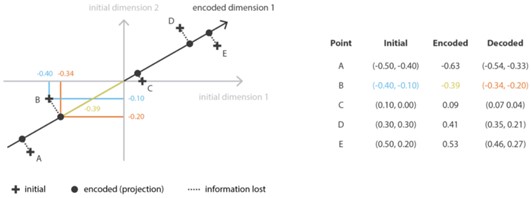
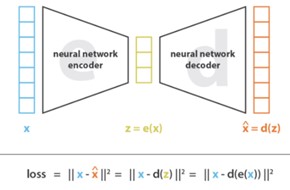
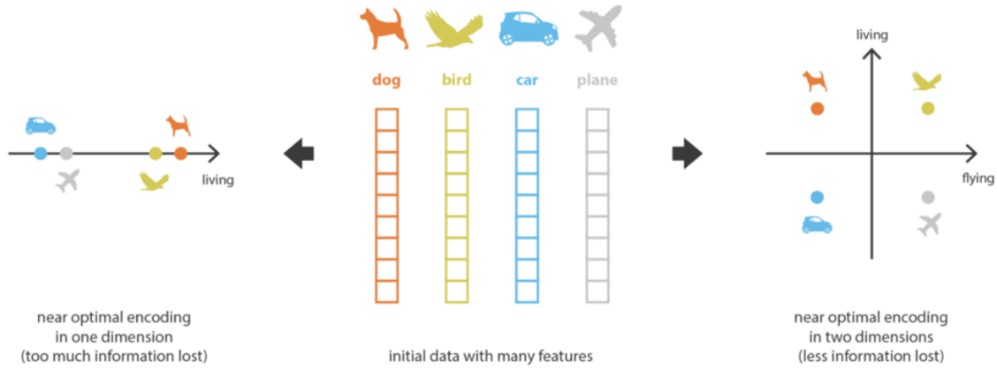
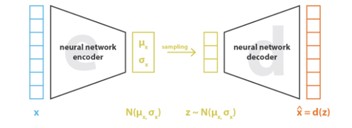
















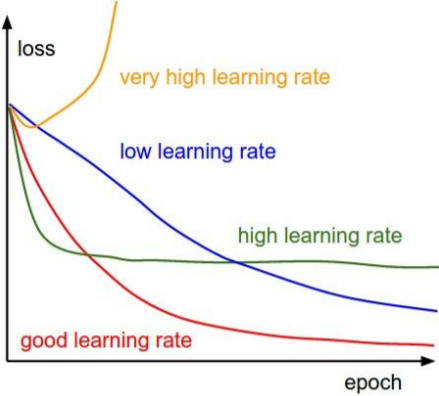
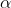 ), בו הוא מוכפל, המווסת את קצב ההתקדמות על מנת שלא נפספס את הנקודה אליה אנו שואפים.
), בו הוא מוכפל, המווסת את קצב ההתקדמות על מנת שלא נפספס את הנקודה אליה אנו שואפים.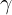 . בכל איטרציה הוא מחשב ה-Gradient צועד לפיו ואז מתקן באמצעות
. בכל איטרציה הוא מחשב ה-Gradient צועד לפיו ואז מתקן באמצעות