
מהי אופטימיזציה ולמה היא משמשת?
אופטימיזציה זוהי פעולה המאפשרת להשיג את התוצאה הקרובה ביותר למטרה שהצבנו בהינתן הכלים שברשותנו ותחת אילוצים מוגדרים (כמו למשל בכמה שפחות זמן וכסף).
סוג האלגוריתם השכיח ביותר באופטימיזציה ובמיוחד בתחום ML, הוא Gradient Descent (להלן: “GD”) . זהו אלגוריתם איטרטיבי המאפשר מינימיזציה של פונקציית ה-loss שאנחנו מגדירים. פונקציית ה-loss הלוא היא פונקציית המטרה שבעזרתה אנו מדריכים את המודל ומסבירים לו אילו פעולות הוא עושה טוב ואילו לא. GD מאפשר לשנות כל פרמטר לחוד בצורה כזו שתקדם את מטרת האופטימיזציה.
אופטימיזציה בעזרת GD היא השכיחה ביותר בתחום ה- Deep Learning בעיקר עקב הדרישה לעדכון מס’ עצום של פרמטרים במהלך ה-Backpropagation.
מה הרעיון הכללי ב-GD?
עבור כל איטרציה t האלגוריתם גוזר את פונקציית ה-loss (מסומנת כ-J) לפי המקדם של המשתנה המסביר, עבור כל אחד מ-d המשתנים הנמצאים בדאטה. וזהו בעצם ה-Gradient, אשר תפקידו להסביר למודל מה הכיוון גודל הצעד שיש לעשות בדרך לאופטימיזציה. לצד ה-Gradient מוגדר שיעור למידה (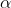 ), בו הוא מוכפל, המווסת את קצב ההתקדמות על מנת שלא נפספס את הנקודה אליה אנו שואפים.
), בו הוא מוכפל, המווסת את קצב ההתקדמות על מנת שלא נפספס את הנקודה אליה אנו שואפים.
להלן האלגוריתמים הנפוצים והשמישים ביותר מתוך: Gradient Descent Optimizers Algorithms
1. Classic GD – זהו האלגוריתם הקלאסי ממשפחת GD, אלגוריתם זה מייצג את המבנה הבסיסי לכל אלו הבאים אחריו. בעזרת גזירת פונקציית Loss, אותה הגדרנו במודל, לפי כל אחד ממקדמי המשתנים (מסומנים כ θ) המסבירים בדאטה, ניתן למצוא את משקל הפרמטרים האופטימלי במודל. GD מתקדם בכל איטרציה בכיוון ה-Gradient כפול עד שהוא מצליח להגיע לנקודה האופטימלית ביותר בהינתן הנתונים ושיעור הלמידה שהכתבנו מראש.
Classic GD Algorithm:
![]()
2. Momentum – ל-SGD יש קושי לנווט בסביבת מינימום מקומי עקב המהירות אליה הוא מגיע, הוא תנודתי מאוד ופחות מכוון. שימוש בשיטת המומנטום עוזר ל-SGD להאיץ בכיוון הנכון ומקטין את התנודתיות באמצעות הוספת פרמטר חיכוך, 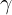 . בכל איטרציה הוא מחשב ה-Gradient צועד לפיו ואז מתקן באמצעות . בפועל Momentum דואג לעדכן ולתת משקל גדול יותר למשתנים בעלי אותו כיוון כמו כיוון הכללי ולהקטין את משקלם של אלו הנמצאים בכיוון ההפוך. על הפרמטר להיות קטן מ-1, ובדרך כלל נהוג לקבוע 0.9 = , אך אין זה מחייב כלל.
. בכל איטרציה הוא מחשב ה-Gradient צועד לפיו ואז מתקן באמצעות . בפועל Momentum דואג לעדכן ולתת משקל גדול יותר למשתנים בעלי אותו כיוון כמו כיוון הכללי ולהקטין את משקלם של אלו הנמצאים בכיוון ההפוך. על הפרמטר להיות קטן מ-1, ובדרך כלל נהוג לקבוע 0.9 = , אך אין זה מחייב כלל.
Momentum Algorithm:


3. Nesterov Accelerated Gradient – אלגוריתם זה דומה ברעיון ל-Momentum, אך עם שיפור נוסף. במקום השימוש בוויסות האלגוריתם רק באמצעות חיכוך, בעזרת NAG האלגוריתם מקבל מושג מה הוא הכיוון שלו מלכתחילה ואיך הוא צריך להתכוונן. NAG מסתמך על כך שהכיוון שאליו הלך בעדכון הקודם הוא אותו כיוון גם בפעם הזו. לכן הוא קודם צועד לפי ה-Gradient שחישב קודם, ומבצע תיקון בעזרת מקדם החיכוך , אחר כך הוא מחשב את ה-Gradient הנוכחי, צועד לפיו ומתקן בעזרת .
NAG Algorithm:

4. Adagrad – זהו אלגוריתם GD עם Learning Rate מותאם, ![]() . Adagrad מתאים שיעור הלמידה אחר לכל אחד מהמשתנים המסבירים. במילים אחרות ופשוטות לכל משתנה מסביר בדאטה יש את הקצב שלו והרעיון הוא לא להשאיר אף מאחור מדי או קדימה מדי. עבור כל אחד מהמשתנים הוא מווסת את גודל הצעד ושואף ליישר קו בין כולם. שיטה זו עוזרת לשמור על יציבות המודל במהלך האימון. על אף יתרונותיו של Adagrad, חולשתו הגדולה מתבטאת בכך שהערך של V גדל חיובי בכל איטרציה, V מתעדכן בעזרת ה-Gradient בריבוע,
. Adagrad מתאים שיעור הלמידה אחר לכל אחד מהמשתנים המסבירים. במילים אחרות ופשוטות לכל משתנה מסביר בדאטה יש את הקצב שלו והרעיון הוא לא להשאיר אף מאחור מדי או קדימה מדי. עבור כל אחד מהמשתנים הוא מווסת את גודל הצעד ושואף ליישר קו בין כולם. שיטה זו עוזרת לשמור על יציבות המודל במהלך האימון. על אף יתרונותיו של Adagrad, חולשתו הגדולה מתבטאת בכך שהערך של V גדל חיובי בכל איטרציה, V מתעדכן בעזרת ה-Gradient בריבוע, ![]() , ומהר מאוד ערכו הופך להיות גדול מדי. שיעור הלמידה מתכווץ מהר לערך קטן מדי, וגורם לכך שתהליך האימון הופך איטי מאוד ופחות יעיל. בסופו של דבר שיעור הלמידה מתכנס לערך השואף ל-0 והמשקולות של הפרמטרים מפסיקות להתעדכן בשלב מוקדם מדי באימון ותהליך האופטימיזציה נפסק.
, ומהר מאוד ערכו הופך להיות גדול מדי. שיעור הלמידה מתכווץ מהר לערך קטן מדי, וגורם לכך שתהליך האימון הופך איטי מאוד ופחות יעיל. בסופו של דבר שיעור הלמידה מתכנס לערך השואף ל-0 והמשקולות של הפרמטרים מפסיקות להתעדכן בשלב מוקדם מדי באימון ותהליך האופטימיזציה נפסק.
Adagrad Algorithm:

5. Adadelta – אלגוריתם זה הוא מעין הרחבה ל-Adagrad אשר בא לפתור את בעיית ההתכנסות המהירה של שיעור הלמידה כלפי מטה. אמנם הרעיון של Adagrad היה להתאים לכל משתנה מסביר שיעור למידה אחר, אך בגלל שפרמטר a שמראש נקבע, האלגוריתם הוגבל וכשל במצבים מסוימים. ב-Adadelta מתגברים על בעיה זו באמצעות הגבלתו של ה-Gradient המצטבר. במקום להשתמש בסכום כל הגראדינטים בריבוע שחושבו עד זמן t, עורכים ממוצע משוקלל המעניק משקל גדול יותר ל-Gradient האחרון שחושב, ז”א 0.5 > . ב-Adadelta אין צורך לקבוע פרמטר מראש משום שבמקומו ניצב ערך המשתנה בהתאם ל-![]() , זהו יתרון מאוד גדול משום שזה מקטין את טווח הטעות, במיוחד בבניית מודלים Deep Learning המכילים שכבות שונות עם התפלגויות משתנות והמון פרמטרים.
, זהו יתרון מאוד גדול משום שזה מקטין את טווח הטעות, במיוחד בבניית מודלים Deep Learning המכילים שכבות שונות עם התפלגויות משתנות והמון פרמטרים.
Adadelta Algorithm:

RMSProp .6 – כמו Adadelta גם אלגוריתם זה פותח במטרה לפתור את בעיית Adagrad. פיתוחו נעשה במקביל ל-Adadelta בצורה בלתי תלויה, וזאת ככל הנראה בשל אותו צורך בפתרון. שיטה זו מתגברת על בעיית ההתכנסות המהירה באמצעות חישוב ממוצע משוקלל של ה-Gradient בריבוע, והענקת משקל גדול יותר ל-Gradient האחרון שחושב, ז”א 0.5 > .
RMSProp Algorithm:

Adam .7 – אלגוריתם משולב, קומבינציה של Mometum ו-RMSProp, אשר גם מתאים שיעור למידה שונה לכל משתנה ומעדכן אותו לפי הקצב שלו. Adam גם מצליח להתגבר על בעיית ההתכנסות המהירה וגם מאפשר טיפול נכון בתנודתיות המתרחשת באזור המינימום המקומי בעזרת השימוש ב-Momentum. בנוסף, בשלב השני לפני עדכון המשקולת, Adam מבצע Bias-correction עקב הטיה בסביבת 0 המתקבלת בזמן האיטרציות הראשונות עקב קבלת ממוצע נע התחלתי באזור ה-0. התיקון הוא עבור שלב האיטרציות הראשונות עד שהפרמטרים ![]() מתכנסים ל-0 ואין צורך עוד בתיקון. בזכות התיקון שמבוצע כאן, Adam מצליח ברוב המקרים לתת תוצאות טובות יותר מ- Adam .RNSProp הוא אחד מהאלגוריתמים החזקים והשימושיים ביותר בתחום בניית רשתות, עקב היכולת שלו להתאים את עצמו לדאטה ושמור על יציבות במהלך האימון.
מתכנסים ל-0 ואין צורך עוד בתיקון. בזכות התיקון שמבוצע כאן, Adam מצליח ברוב המקרים לתת תוצאות טובות יותר מ- Adam .RNSProp הוא אחד מהאלגוריתמים החזקים והשימושיים ביותר בתחום בניית רשתות, עקב היכולת שלו להתאים את עצמו לדאטה ושמור על יציבות במהלך האימון.
Adam Algorithm:

Nadam .8 – אלגוריתם המשלב בין Adam לבין NAG. אלגוריתם זה מיושם במקרים בהם יש Gradient רועש או עקמומי. זהו שילוב של שתי שיטות מוצלחות בתחום, המסוגל לתת תוצאות טובות במקרים מסוימים.
Nadam Algorithm:

באיזה Optimizer משתמשים ומתי?

כמו ברוב המקרים בתחום אין באמת כלל אצבע או מתכון מדויק. לא כל Optimizer נכון לכל סיטואציה, יש כאלו שנותנים ביצועים טובים יותר במשימות Computer Vision, חלקם עדיפים בשימוש ברשתות RNN וחלקם למצב בו הדאטה רחב יותר. אך בכל אחד מהמקרים האלו יכול לקרות שאלגוריתם שבדרך כלל טוב למטרה x נותן תוצאות מעולות עבור מקרה y ולכן אין הגדרות נחרצות לאופן השימוש.
הסיכוי הטוב ביותר למציאת האלגוריתם הנכון היא לחקור אילו מהם הצליחו להגיע לתוצאות טובות בפתרון בעיה הדומה לזו שלכם, זאת אומרת דמיון במבנה הנתונים ודמיון במודל שאתה מעוניינים לבנות. לא בטוח שזה יבטיח פתרון עבורכם אבל ככל הנראה זה ייתן לכם את הכיוון שממנו נכון להתחיל.
