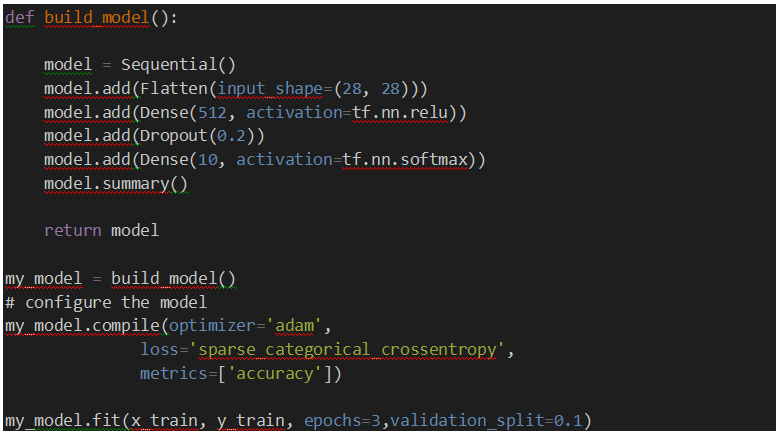
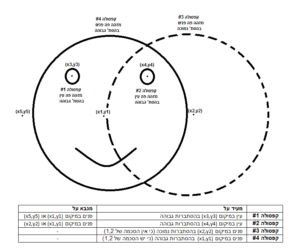
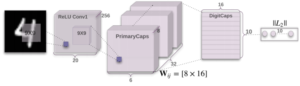
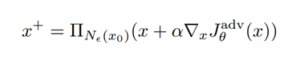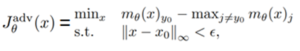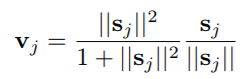בעולם לימוד המכונה, וקל וחומר בתחום של למידה עמוקה אנו נדרשים לתת פרדיקציות על קלטים שלעיתים מאוד מסובכים (מבחינה מתמטית), כגון תמונות, קטעי וידאו, קטעי קול ועוד. באופן כללי, כאשר נרצה לתת פרדיקציה, נוכל לבצע זאת באחת מ-2 הדרכים הבאות:
- בניית מודל מאפס
- שימוש במודל קיים ומאומן כדי להיעזר במשקלים שלו. (Transfer Learning)
במאמר זה נתמקד באפשרות השניה.
ישנם מספר מודלים אשר יכולים לעזור לנו לבצע העברת לימוד (Transfer Learning) או כיוונון סופי (Fine-Tuning) בצורה טובה ויעילה.
מהי העברת למידה?
לולא העברת הלמידה, לימוד המכונה היה דבר קשה למדי עבור אדם מתחיל. ברמה הכללית ביותר, לימוד מכונה כרוך בחישוב פונקציה הממפה כמה קלטים והפלטים המתאימים להם. אף על פי שהפונקציה עצמה היא רק אסופה של פעולות מתמטיות כגון הכפלה וחיבור, כאשר נעביר אותה דרך פונקציית הפעלה לא-ליניארית ונקבץ יחדיו חבורה של כמה שכבות כאלו, הפונקציות הללו יוכלו ללמוד כמעט כל דבר, כמובן בתנאי שיש מספיק נתונים ללמוד מהם וכמות מספיק גדולה של כוח חישובי.
איך זה עובד?
לדוגמה, בראייה ממוחשבת, רשתות עצביות בדרך כלל מנסות לזהות קצוות בשכבות המוקדמות שלהן, צורות בשכבות האמצעיות שלהן וכמה תכונות ספציפיות למשימה שלנו בשכבות המאוחרות יותר. עם העברת הלמידה, אנו יכולים להשתמש בשכבות המוקדמות ובשכבות האמצעיות ולאמן מחדש את השכבות האחרונות בלבד. דבר זה עוזר לנו למנף את הנתונים המתוייגים עליהם אומן המודל בתחילה.
נקח לדוגמה מודל שאומן לזיהוי תרמילים בתמונה, וננסה להשתמש בו כדי לזהות משקפי שמש. בשכבות הראשונות, המודל למד לזהות חפצים כללים ומפאת כך, נוכל להשתמש במודל ולאמן מחדש רק את השכבות האחרונות שלו, כך שהוא ילמד מה מפריד את משקפי השמש מחפצים אחרים.
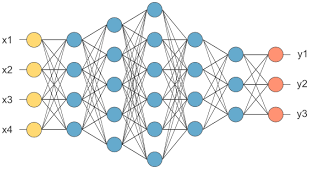
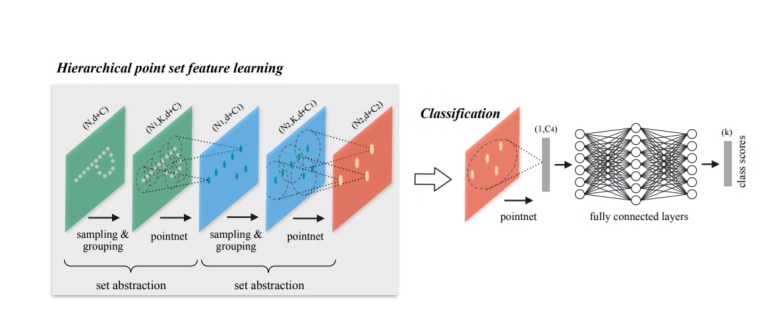
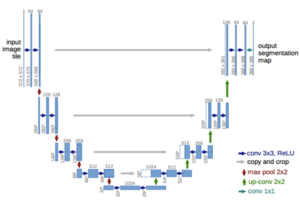
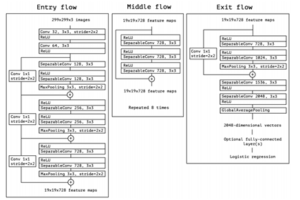
המודל למעשה יהיה בארכיטקטורה הבאה:

בהעברת הלמידה, אנו מנסים להעביר ידע רב ככל האפשר מן המשימה הקודמת, עליו המודל כבר אומן, למשימה החדשה שלנו כעת. הידע יכול להיות במגוון צורות בהתאם לבעיה ולנתונים. לדוגמה, הצורה שבה המודלים מורכבים יכולה להיות זו שתאפשר לנו לזהות ביתר קלות אובייקטים חדשים.
מדוע משתמשים בהעברת למידה?
לשימוש בהעברת למידה יש מספר יתרונות שנדון בהם כעת. היתרונות העיקריים הם חסכון בזמן אימון, הרשת העצבית תפעל בצורה טובה יותר ברוב המקרים וכן לא נצטרך הרבה נתונים.
בדרך כלל, אנו צריכים הרבה נתונים כדי לאמן רשת עצבית מאפס אבל לא תמיד יש לנו גישה למספיק נתונים. זה המקום שבו העברת למידה נכנסת למשחק.נוכל לבנות מודל יציב עם כמות יחסית קטנה של נתונים לאימון, כיוון שהמודל כבר אומן מראש. לכן, ניתן לחסוך הרבה מאוד זמן של אימון, דבר משמעותי מאוד מכיוון שאימון של רשת עצבית עמוקה מאפס יכול לעיתים לקחת ימים או אפילו שבועות למשימה מורכבת.
כלומר, למעשה נחסוך בשתי דרכים:
1: הקטנת הדאטה הנדרש – לא יהיה צורך במערך אימונים גדול במיוחד.
2: הקטנת הכוח החישובי הנדרש. היות ואנו משתמשים במשקולות אשר אומנו מראש ונותר רק ללמוד את המשקולות של השכבות האחרונות.
מתי כדאי להשתמש בהעברת למידה?
כמו ברב המקרים של למידת מכונה, קשה ליצור כללים קשיחים החלים תמיד. אך אנסה לספק כמה הנחיות כלליות.
בדרך כלל כדאי להשתמש בהעברת למידה כאשר:
(א) אין ברשותך מספיק נתוני אימון מתוייגים כדי לאמן את הרשת שלך מאפס
(ב) כבר קיימת רשת אשר אומנה מראש על משימה דומה, ובד”כ על כמויות אדירות של נתונים.
(ג) מקרה נוסף שבו השימוש יהיה מתאים הוא כאשר למשימה 1 ולמשימה 2 יש את אותו קלט. (למשל תמונה באותו הגודל)
אם המודל המקורי אומן באמצעות TensorFlow, ניתן בפשטות לשחזר אותו לאמן אותו מחדש על כמה שכבות כדי שיתאים למשימה שלך. יש שים לב כי העברת הלמידה עובדת רק כאשר התכונות הנלמדות מהמשימה הראשונה הן גנריות, ולפיכך יכולות להיות שימושיות גם למשימה דומה אחרת. (למשל זיהוי תבניות כלליות בתמונה כמו קווים, עיגולים וכו’…)
כמו כן, הקלט של המודל צריך להיות באותו גודל כפי שהוא היה כאשר אומן בתחילה. אם אין המצב כך, יש להוסיף שלב עיבוד מקדמי כדי לשנות את גודל הקלט שלנו לגודל הנדרש.
אילו מודלים יעזרו לנו בהעברת הלמידה?
ישנם מספר מודלים מפורסמים אשר לכל אחד היתרונות שלו. אנו נדון בכמה מהמפורסמים והעדכניים יותר.
מודל VGG16
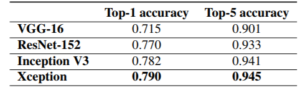
VGG16 פורסם בשנת 2014 והוא אחד מסוגי הרשתות הפשוטות ביותר (בין ארכיטקטורות ה – CNN האחרות שהיו בתחרות Imagenet). רשת זו מכילה סה”כ 16 שכבות מתוכם 13 שכבות קונבלוציה ו 3 שכבות Dense לצורך הסיווג. מספר הפילטרים בשכבות בקונבלוציה הולכים וגדלים בעוד המימדים הגיאומטריים הולכים וקטנים.
החסרונות של ארכיטקטורה זו הינם:
- שלב האימון הינו איטי יחסית
- התהליך מייצר מודל גדול מאוד.
הארכיטקטורה של VGG16 ניראת כך:

https://www.semanticscholar.org/paper/Face-Recognition-across-Time-Lapse-Using-Neural-Khiyari-Wechsler/1c147261f5ab1b8ee0a54021a3168fa191096df8
באם נבחר להשתמש במודל זה, אנו נבצע את הצעדים הבאים כדי לממש את VGG16:
- נייבא את האפליקיישן של VGG16 מ- applications
- נוסיף את המשקולות השמורים לארכיטקטורה (weights = ‘ImageNet’)
- נשתמש במודל כדי לבצע תחזיות
- אציין כי קיימת רשת דומה מאוד בשם VGG19 אשר מכילה מאפיינים דומים למה שתואר לעיל.
מודל InceptionNets
רשת הידועה גם בשם “GoogleNet“. המורכבת מסה”כ 22 שכבות והייתה המודל המנצח בתחרות ImageNet של שנת 2014.
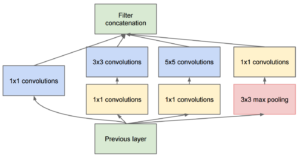
מודולי Inception הם אבן היסוד של InceptionNets והרעיון המרכזי של מודול ה – Inception הוא לעצב טופולוגיה של הרשת המקומית בצורה טובה (כלומר רשת בתוך רשת).
מודלים אלו משתמשים בקונבלוציות בגדלים שונים כדי ליצור Feature-Map מגוון.
בנוסף, הם גם מכילים קונבלוציה של 1X1 כדי לבצע הפחתת מימדים.
על ידי ביצוע קונבלוציית ה – 1X1, המודל משמר את הממדים המרחביים אך מפחית את העומק. כך שהמימדים של הרשת הכוללת לא גדלים באופן אקספוננציאלי.
מלבד שכבת הפלט הרגילה, רשת זו מורכבת גם משני פלטי סיווג עזר המשמשים להזרקת Gradients בשכבות נמוכות יותר. כך ניראת כל שכבה Inception:
https://arxiv.org/pdf/1409.4842.pdf
והארכיטקטורה השלמה ניראת כך:

https://arxiv.org/pdf/1409.4842.pdf
מודל Resnets
כל המודלים הקודמים השתמשו ברשתות עצביות עמוקות שבהן הם ערמו שכבות קונבלוציה רבות אחת אחרי השנייה. ניראה היה כי רשתות שהן עמוקות יותר מביאות לביצועים טובים יותר.
עם זאת, לאחר יציאת מודל Resnet התברר כי הדבר לא ממש מדויק. להלן הבעיות עם רשתות שהן עמוקות יותר:
- קשה לגרום לרשת להתכנס לפתרון (בשלב האימון)
- עלולה להיווצר בעיה של היעלמות / פיצוץ של גרדיאנטים.
- הדיוק בתחילה עולה עד שמגיע לרוויה ואז נופל.
כדי לטפל בבעיות הנ”ל, מחברי הארכיטקטורה Resnet הגו את הרעיון של “לדלג על קשרים” עם ההשערה כי השכבות העמוקות צריכות להיות מסוגלות ללמוד כמו השכבות הרדודות. פתרון אפשרי הינו העתקת האקטיבציות מהשכבות הרדודות וקביעת שכבות נוספות למיפוי הזהויות.
כפי שמופיע באיור להלן:

https://towardsdatascience.com/an-overview-of-resnet-and-its-variants-5281e2f56035
תפקידם של קשרים אלו הוא לבצע פונקצית זהות על האקטיבציה של השכבת הרדודה (הראשונית), אשר בתורה תייצר את אותה אקטיבציה. לאחר מכן, הפלט מתווסף לאקטיבציה של השכבה הבאה. כדי לאפשר קשרים אלו, ובכלל לאפשר את האופרציות הנוספות הללו, יש צורך להבטיח את אותן מימדים של קונבלוציות לאורך כל הרשת. זו הסיבה שלמודלי Resnets יש את אותן קונבלוציות של 3 על 3 לאורך כל הדרך.
באמצעות בלוקים שיוריים ברשת, ניתן לבנות רשתות בכל עומק שהוא תחת ההבנה כי שכבות חדשות למעשה מסייעות ללמוד תבניות חדשות בנתוני הקלט. מחברי המאמר יצרו ארכיטקטורת רשת עצבית עם 152 שכבות. הסוגים השונים של Resnets כגון Resnet34, Resnet50, Resnet101 הפיקו את הפתרונות עם דיוק גבוה מאוד בתחרויות Imagenet.
הרעיון מאחורי אותם מעקפים הוא שבמקרה “הגרוע ביותר”, השכבות הנוספות לא למדו כלום והרשת תיתן את הפרגיקציה הטובה ביותר בהתבסס על המעקפים, ובמקרה הפחות גרוע יכול להתברר כי השכבות הנוספות למדו משהו שימושי ובמקרה זה, הרי שביצועי הרשת השתפרו.
לפיכך, הוספת בלוקי שיורית / קישורי דילוג לא פוגעות בביצועי הרשת ולמעשה מגדילות את הסיכויים כי שכבות חדשות ילמדו משהו שימושי.
לסיכום
בפוסט זה, דנו מהי העברת הלמידה, מדוע היא חשובה ואיך היא נעשת תוך כדי ציון כמה מהיתרונות שלה. דיברנו מדוע העברת הלמידה יכולה להקטין את כמות הנתונים שלנו בצורה משמעותית וכן להקטין את זמן האימון. כמו כן עברנו על מתי ראוי לבצע העברת למידה ולבסוף תיארתי אוסף של מודלים שכבר אומנו מראש ובהם ניתן להשתמש בהעברת למידה למודלים\בעיות שלנו.