
“מחקר בן שנתיים קובע שלמידה אורכת זמן כפול כשהטלוויזיה דלוקה. המחקר היה אמור לארוך רק שנה, אבל הטלוויזיה הייתה דלוקה.”- ג’יי לנו
נחמד לצפות בסרטונים משעשעים בוואטסאפ, אבל לא תמיד יש זמן לצפות בסרטון של 7 דקות על אחיינית שאוכלת גלידה. היינו רוצים איזו תוכנה שתאמ;לק לנו סרטונים, ותציג לנו סרטון קצר שמתמקד בחלקים המעניינים – החלק בו האחיינית מכבדת את אחותה בגלידה לאחר שזאת נפלה על הרצפה.
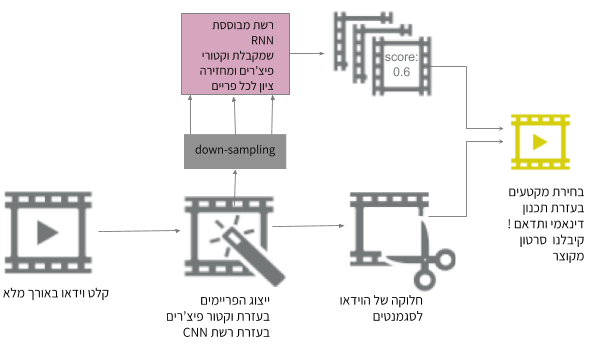
סיכום וידאו (video summary) הוא תהליך בו בהינתן סרט, יש לבחור תת קבוצה של פריימים המכילים את המידע החשוב ויוצרים סרטון מגוון תוך שמירה על הרצף ויזואלי-תוכני (בדומה לעריכת וידאו אנושית).
להלן דוגמה של וידאו מקורי ומשעמם באורך 1:25 (הלקוח מאגר וידאוים לבעיית התימצות: tvsum)
ולהלן הוידאו המתומצת שלו באורך 12 שניות כפלט מאלגוריתם הזה (רק שיניתי אותו בזה שהחלפתי את הרשת שמקודדים איתה את הפריימים inception v3 במקוםinception v1)
איך קובעים את מידת החשיבות של פריים?
חשיבות הפריימים היא דבר סובייקטיבי. בלמידה מונחית (supervised), למידה מבוססת מידע מתויג, משתמשים בדירוג אנושי. עבור כל סרטון מבקשים ממספר אנשים לסווג כל פריים למעניין או לא מעניין, ממצעים את הדירוגים ומקבלים ציון שמייצג את רמת העניין של הפריים. אם פריים מסויים עניין 7 מתוך 10 אנשים הוא יקבל ציון 0.7. כך מייצרים את המידע המתוייג.
איך יוצרים רשת שמדרגת את החשיבות של כל פריים?
בניגוד לתמונה, רמת העניין של פריים תלויה ברצף הפריימים ומיקומו בתוך הוידאו. בשביל לתת ביטוי למיקום הפריים ברצף, משתמשים ברשתות נוירונים ממשפחת (Recurrent Neural Network (RNN או Self-Attention אשר נועדו לפענח מידע סדרתי. רשתות אלו יכולות לקבל מידע סדרתי בכל אורך, לצורך עניינינו סרטונים עם מספר פריימים שונה. בנוסף לכך הן כוללות מרכיב של זיכרון – כך שהרשת “יודעת להתחשב” בהיסטוריה.
רשת RNN בסיסית

בתרשים רואים מבנה רשת RNN בתצוגה מקופלת (שמאל) ובתצוגה פרושה (ימין). רשת כזו מקבלת מידע סדרתי X ומחזירה פלט סדרתי O.
Xt הוא הקלט ה-t ברצף הזמן, במקרה שלנו הפריים ה -t
ht הוא מצב נסתר (hidden state) בזמן t, ה”זיכרון” של הרשת. ht מחושב על סמך המצב הנסתר הקודם (ht-1) והקלט בשלב הנוכחי (Xt).
ot הפלט של זמן t, במקרה שלנו התחזית של הרשת לגבי כמה מעניין הפריים ה-t.
בעיות זיכרון
הכנסת וידאו שלם לרשת RNN זה דבר כבד! נדרש לשם כך זיכרון רב. על מנת לפתור את הבעיה משתמשים בשתי טכניקות:
- Down-Sampling לסרטון. במקום להתחשב ב-30 פריימים לשנייה אפשר להסתכל רק על 2, תחת ההנחה שאין הבדל גדול בין פריימים עוקבים.
- במקום לקחת את הפריימים עצמם, מתמצתים את המידע שנמצא בתמונה. דבר זה מתבצע על ידי הוצאת מאפיינים בעזרת רשתות קונבולוציה (CNN) שאומנו למטרות סיווג תמונות (כגון VGG, GoogLeNet, ResNet)
איך שומרים על רציפות הסרטון?
אחת הדרכים לתמצת סרטון מתחילה בלבקש מהמשתמש את אורך הסיכום הדרוש. לאחר מכן, מחלקים את הוידאו למקטעים בצורה חכמה על ידי אלגוריתם למציאת נק’ שינוי סצנה (למשל Kernel Temporal Segmentation). נקודות השינוי ישמשו להגדרת הסוף וההתחלה של כל מקטע. במקום שהאלגוריתם יבחר באופן נפרד כל פריים, הוא בוחר אילו מקטעים לקחת. באופן זה נשמרת הרציפות בסרטון המקוצר.
איך בוחרים אילו מקטעים לקחת? (בעיית תרמיל הגב)
נרצה לבחור מקטעים כך שאורכם לא יעלה על אורך הסרטון המבוקש, וסכום ציוני הפריימים שלהם יהייה מירבי.
בעייה זו שקולה לבעייה מפורסמת מאוד במדעי המחשב שנקראת בעיית תרמיל הגב (Knapsack problem) .
בעיית תרמיל הגב – נתונה קבוצת עצמים (למשל פריטים בחנות) שלכל אחד מהם משקל ומחיר, ונתון חסם על המשקל המירבי שניתן לסחוב בתרמיל. המטרה היא למצוא אוסף של העצמים שסכום משקליהם אינו עולה על המשקל שניתן לסחוב, וסכום מחיריהם מקסימלי. במקרה שלנו ה”משקל” של מקטע הוא האורך שלו, וה”מחיר” הוא סכום ציוני רמת העניין. את החסם על המשקל המירבי מחליף אורך הסרטון המבוקש.
בעייה זו מוגדרת כבעייה np-קשה, עם זאת, כאשר משקלי כל הפריטים שלמים, ניתן לפתור אותה בעזרת תכנון דינאמי בסיבוכיות זמן (O(Wn, כאשר W הוא המשקל המירבי שניתן לסחוב ו-n כמות הפריטים. במקרה שלנו המשקלים הם מספר הפריימים בכל מקטע, כלומר מספרים שלמים.
איך אומדים את טיב הסרטון?
יצרנו מערכת שבוחרת אילו פריימים נכנסים לסרטון המקוצר. אחת הדרכים למדוד את טיב הבחירה היא להשתמש במדד F-score , מדד סטטיסטי לבדיקת דיוק שמתחשב ב-
Recall = TP/(TP+FN)
וב-
Precision = TP/(TP+FP)
כאשר TP=True Positive זה כשהאלגוריתם חזה שהקטע מעניין וצדק
ו FN=False Negative זה כשהאלגוריתם חזה שהקטע לא מעניין וטעה
ו FP=False Positive זה כשהאלגוריתם חזה שהקטע מעניין וטעה.

מדד F-score מוגדר באופן הבא:

סיכום
סקרנו את התהליך של סיכום וידאו באמצעות רשתות נוריונים על בסיס מידע מתוייג וכיצד מודדים את תוצאות האלגוריתם. נסכם את התהליך:
- מייצגים כל פריים על ידי וקטור פיצ’רים, באמצעות רשת קונבולוציה.
- מחלקים את הוידאו לסצנות באמצעות אלגוריתם למציאת נק’ שינוי המקבל כקלט את וקטורי הפיצ’רים של הפריימים
- מורידים את ה-(fps (frame per second של הסרטון
- מכניסים את וקטורי הפיצ’רים לרשת מבוססת RNN שמחזירה את החשיבות של כל פריים.
- משתמשים בתכנון דינאמי לבעיית תרמיל הגב בשביל לבחור אילו מקטעים להכניס לסרט המקוצר בהתאם להגבלת אורך שהגדרנו.
הפוסט מבוסס ברובו על האלגוריתם המוצע במאמר Summarizing Videos with Attention שמבצע למידה מונחית (supervised)
ישנם הבדלים במימושים של מאמרים שונים, אבל רובם פועלים ברוח דומה. ישנם גם אלגוריתמים לא מונחים (unsupervised) לבעייה זו שעובדים היטב. אפשר לקרוא עליהם בקצרה בפוסט הזה.
