אז אחרי שבניתי את הרובוט הזה (ראו את התמונה בעמוד הראשי של כל הכתבות) אני רוצה להכניס לו קצת בינה ודעת…
מטרתי הייתה ללמוד ולהתנסות ב Reinforcement Learning כי זה תחום מאוד מסקרן, בטח אחרי כל משחקי האטארי המפוצחים ע”י אלגוריתם (חודשים של התמכרות כשהייתי בן שבע 🙂 מעניין איך המחשב משחק בזה ? ? ?)
אז המצאתי בעיה שנראית פשוטה: סוכן שחי בלוח משבצות ומטרתו להגיע אל הכדור שמונח איפשהוא ולהביאו לשער (שתי המשבצות האדומות). כאשר הפעולות האפשריות הינן לפנות ימינה או שמאלה (סיבוב במקום ב 45 מעלות), ללכת קדימה או אחורה, או להרים כדור (פעולה שרלוונטית רק כשהסוכן במשבצת של הכדור).
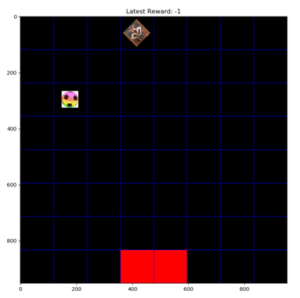
בן אנוש ממוצע פותר את המשחק הזה די מהר (כולל להבין מהם החוקים בכלל, ז”א איך אמורים לנצח מבלי שמספרים לו גם איך משחקים) וניסיתי מספר גישות בסיסיות של RL לפתור את הבעיה. היופי בגישת ה RL היא שלא מכניסים לאלגוריתם שום מודל המבוסס על חוקי המשחק, ולכן מדובר פה בתהליך ניסוי וטעייה מאפס.
קצת טרמינולוגית RL
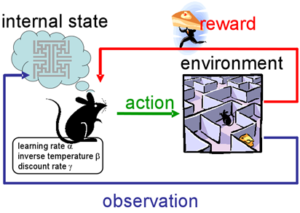
תודה ל https://becominghuman.ai/the-very-basics-of-reinforcement-learning-154f28a79071
State = מצב בו נמצא הסוכן (סך המידע הגלוי לו על הסביבה שלו). אפשר שמצבים יחשבו כראשוניים או כסופיים (ז”א תחילת\סוף משחק). במקרה של המשחק המתואר, מצב הינו: מיקומו של הסוכן על לוח המשבצות, מיקומו של הכדור על לוח המשבצות, ומשתנה בינארי שמשמעותו אם הכדור מוחזק ע”י הסוכן או לא.
Action = פעולה אותה יכול הסוכן לעשות בכל מצב. הפעולה תעביר אותו למצב חדש או תשאיר אותו בנוכחי. במקרה של המשחק המתואר זה ערך מספרי בדיד בין 1 ל-5: מעלה, מטה, ימינה, שמאלה, הרם.
Episode = אפיזודה\משחק שלם. ז”א שרשרת של מעברים ממצב ראשוני כלשהוא למצב סופי כלשהוא. במקרה של המשחק המתואר זה שרשרת המצבים מתחילת המשחק עד שהכדור מוחזק ע”י הסוכן והסוכן מגיע למשבצות האדומות.
Reward = תגמול אותו מקבל הסוכן כתוצאה מצמד (פעולה, מצב קודם). במקרה של המשחק המתואר החלטתי לתת תגמול גבוה במקרה של נצחון, תגמול נמוך במקרה של הגעה של הסוכן למיקום הכדור והרמתו. ערכי התגמולים הם פרמטרים איתם שיחקתי (למשל בקוד כפי שתוכלו לראות זה כרגע 20, 5). כמו כן שיחקתי עם אפשרות לתת תגמול שלילי (ז”א עונש) על כל תור שחולף. שיטה זו בעצם גורמת לסוכן להתאמן על לנצח מהר ולא סתם לנצח. כי בכל תור בו עשה פעולה מיותרת הוא משלם מחיר…
π=Policy = מדיניות לפיה מחליט הסוכן איזו פעולה לבחור בכל מצב. למעשה פונקציה המקבלת מצב ומחזירה פעולה. בקוד תוכלו לראות שתי גישות אותן ניסיתי (ε-Greedy או Softmax Action Selection).
Return=G = סכום התגמולים שנתקבלו החל מצמד (פעולה, מצב) ועד לסיומה של האפיזודה
Quality=Q = טבלת הערך לכל צמד (פעולה, מצב). מחושב למשל כממוצע של כל ה-G שנתקבלו עבור על צמד (פעולה, מצב). המשמעות הינה כמה מוצלחת הפעולה הזו בהינתן המצב הזה?
Value=V = טבלת הערך לכל מצב. (לעיתים משתמשים ב V ולעיתים ב Q) המשמעות הינה עד כמה כדאי להימצא במצב הזה ? (מבחינת אפשרויות לנצחון)
עיקר האתגר הוא לשערך את הערכים האופטימליים ל Q או V כי ידיעתם משמעותה איך הכי נכון לפעול. (ז”א איזו פעולה הכי כדאי לבחור בהינתן שהסוכן במצב מסוים)
אילו יש בידינו (בידי הסוכן) את הערכים האופטימליים לכל מצב\פעולה אז ישנן מדינויות (Policies) לפעול כמו ε-greedy או softmax action selection. הרחבה על נושא זה תמצאו בכתבה הזו.
בכתבה זו נעסוק במספר שיטות לעידכון פונקציות הערך Q או V.
שיטת מונטה קרלו
בשיטת מונטה קרלו משחקים הרבה אפיזודות מההתחלה עד הסוף כדי לעדכן את טבלת הערך (Q).
העידכון הכי טריוויאלי יכול להיות פשוט התגמול המתקבל, ז”א יש טבלה גדולה של כל הצמדים האפשריים (מצב, פעולה) ובכל פעם שמתקבל תגמול במהלך המשחק מעדכנים ערך בטבלה.
לפי שיטה זו עלינו קודם לאמן, ורק לאחר האימון נוכל להשתמש במדיניות (Policy) אופטימלית בהתבסס על טבלת ה Q שחושבה באימון.
להבדיל משיטת מונטה קרלו, ישנן שיטות בהן תוך כדי המשחק כבר מתפתחת מדיניות בה ניתן להשתמש. (ז”א לא צריך לחכות לסוף האימון כדי לשחק את החיים האמיתיים)
שיטת Q-Learning
בשיטה זו גם מנהלים טבלה של ערכי Q אך מעדכנים אותה בכל איטרציית משחק על פי הנוסחה הבאה:
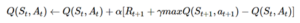
הערך Q עבור בחירת פעולה מסויימת At במצב מסויים St (בזמן\תור t) הינו הערך שהיה ועוד קומבינציה לינארית בין התגמול שנתקבל מפעולה זו לבין הערך הגבוה ביותר שניתן לקבל בעבור המצב הבא. (ע”י השוואה בין כל הפעולות האפשריות מהמצב החדש)
ראו כתבה קודמת ממוקדת על שיטה זו.
להלן גרף (מתקבל מהקוד, ראה קישור למטה) המתאר את מספר שתורות למשחק כפונקציה של המשחקים באימון על פי שיטה זו:

ניתן לראות בבירור שלאחר 100,000 משחקונים האלגוריתם כבר בנה טבלת Q מוצלחת כך שמצליח לפתור כל משחק במעט תורות.
שיטת Deep Q-Learning
בשיטה זו רשת נוירונים מקבלת כקלט את המצב ואת הפעולה ומחזירה את הערך (פונקציית Q), או כפי שעשו DeepMind במשחקי האטארי שלהם, הרשת מקבלת רק את המצב (למעשה התמונה במשחק) ומחזירה את הערך (Q) של כל אחד מהמצבים הבאים האפשריים. מספר המוצאים כמספר הפעולות האפשריות.

גם כאן ניתן לפעול לפי מדיניות כלשהיא, למשל ε-Greedy או Softmax Action Selection או כל מדיניות אחרת שמשתמשת ב Q שהרשת מספקת לכל מצב. ואת הלימוד (back propagate) של הרשת מבצעים באופן דומה ל Q Learning, תוך כדי המשחק. התהליך כולו (עליו חוזרים לאורך אפיסודות\משחקים רבים) נראה כך:
- מזינים את המצב הנוכחי לרשת ומקבלים וקטור q1 (ערך לכל פעולה אפשרית). הפעלת זו של הרשת הינה רק קדימה ז”א ללא אימון BackPropagation.
- בוחרים פעולה ומשחקים אותה (או בעלת הערך הגבוה ממה שיצא ברשת או אקראי תלוי במדיניות)
- מזינים את המצב הנוכחי (שהוא החדש) לרשת ומקבלים וקטור q2 (זו שוב הפעלת הרשת קדימה ז”א ללא אימון עדיין)
- בונים וקטור פרדיקציה (שישמש לשלב האימון) באופן הבא:
לוקחים את הווקטור q1 כאשר מחליפים בו את האלמנט של הפעולה בה בחרנו ושמים שם ערך חדש לפי נוסחת ה- Q-Learning:

המשמעות הינה: היינו רוצים לאמן את הרשת להוציא ערך על הפעולה שבחרנו שהינו התגמול על הפעולה ועוד הערך המירבי של המצב הבא.
האינטואיציה לכך: מצב ייחשב מוצלח אם ניתן להגיע ממנו למצב מוצלח אחר. (כמו במשחק השחמט: אומרים “שח” כי זה מצב ממנו ניתן לנצח בתור הבא)
- שלב האימון: מזינים (שוב) לרשת את המצב הקודם אך הפעם גם מריצים אחורה עם פונקציות מחיר של השוואה עם וקטור הפרדיקציה שחושב בשלב הקודם.
כשאימנתי לפי שיטה זו היו דרושים יותר משחקי אימון (מאשר בשיטת Q-Learning) כדי להגיע להצלחה, אני מניח שזה מכיוון שזה קצת overkill לבעיה. היתרון הגדול בשימוש ב CNN לבעיות כאלו הם כשהמצב (state) הינו תמונה (כמו במשחקי אטארי) ולא וקטור או מטריצה (תמציתית) המתארת את המצב הנוכחי במשחק. במקרים שהמצב הוא תמונה, לתחזק טבלת ערכים לכל מצב אינו ריאלי.
טיפים לניפוי הקוד
לא תופתעו אם אספר שבהרצות הראשונות האימון לא התכנס, או התכנס והסוכן למד לשחק לא טוב. עבור מישהו כמוני שמנוסה בראייה ממוחשבת וברשתות CNN שם פיתחתי אינטואיציה מסוג מסויים היה לי די קשה לדבג את הקוד הזה. כי פה מדובר בסוכן שכל פעם לומד חלק מאוד קטן ממרחב האפשרויות האפשרי במשחק. ואיך לימוד בנקודה מסוימת משפיעה על אחרת ואיך יודעים מה לצפות כשמריצים ניסיון כלשהוא ?
הניסיון שצברתי בפרויקטון זה איפשר לי לרכז כמה טיפים שעזרו לי לדבג ולגרום למערכת לעבוד לבסוף:
- חישוב והצגה של גרף של כמות האיטרציות כפונקציה של מספר האפיזודות (המשחקים) אליהן אומן הסוכן אמור להיות גרף יורד. מדד זה סיפק לי מידע אם אני בכיוון הנכון בכל הרצה. במילים אחרות: ככל שהסוכן מתאמן יותר, הוא אמור לנצח יותר מהר במשחק.
- להשוות ביצועים של סוכן שמתנהג בצורה אקראית לגמרי (כמה תורות בממוצע ינצח במשחק ?) לעומת מודל מאומן.
- לייצר ויזואליזציה של המשחק (זה מומלץ בכל domain), לאפשר לי משחק אינטראקטיבי (ז”א שאוכל לשחק כנגדו) שיגרום לי להבין מה בכל זאת למד המודל. למשל למד אסטרטגיות כאלו שמביאות אותו לפעולות מחזוריות ולכן לתקיעות. בכל צעד שהמודל “משחק” להציג את השיקולים שלו (ז”א את ערכי ה Q לאותו המצב)
- להתחיל במקרה פשוט ולאט לאט לסבך אותו (זה גם מומלץ בכל domain). במקרה זה התחלתי בלוח פשוט ביותר של 2×2 כאשר מצב הפתיחה קבוע. ואז מצב פתיחה אקראי, ואז הגדלת גודל לוח המשחק, וכו’
הסבר על הקוד
את הקוד תמצאו ב GitHub שלי !
Solve_game.py זהו הקוד הראשי שפותר את המשחק לפי כל אחת מהשיטות (זה הקוד שיש להריץ).
Game.py המחלקה המממשת את המשחק עצמו, מאפשרת לאתחל משחק לפי פרמטרים שונים, להקליט משחק, לשחק (לא משנה אם אדם או אלגוריתם), להציג לוח משחק ועוד… שימו לב למטודה state_as_tensor שמחזירה את מצב המשחק כטנזור בגודל nxnx2. כאשר n הוא גודל לוח המשבצות וערוץ אחד עבור מיקום הסוכן והערוץ השני עבור מיקום הכדור ומצבו (מוחזק או לא מוחזק ע”י הסוכן)
interactive_play.py מאפשר למשתמש (אנושי) לשחק במשחק
policies.py מאפשר מדיניות משחק: אפסילון החמדן (Greedy Epsilon) או Softmax Selection. בפרט שליטה על דעיכת הפרמטר אפסילון (ε).
Deep_Q_learning.py מימוש שיטת Deep-Q Learning כמוסבר מעלה.
tabular_learning.py מימוש שיטות מונטה קרלו או Q-Learning כמוסבר מעלה.
לסיכום
מאוד התרגשתי כשראיתי את הסוכן המאומן שלי משחק בעצמו במשחק ומנצח מהר, ז”א ללא צעדים מיותרים!
ראו סרטון שמדגים את תהליך הלמידה: (בהתחלה משחק אקראי וככל שמתקדם האימון משחק יותר ויותר בהגיון):
השלב הבא של הפרויקט הוא לעבוד עם משתנה מצב תמונה (ז”א אוסף פיקסלים) ואז לבחון ביצועים. כמו כן לחפש דרכים איך להקטין את משך האימון ולממש Double Q-Learning.
אשמח לשאלות ופידבקים!


