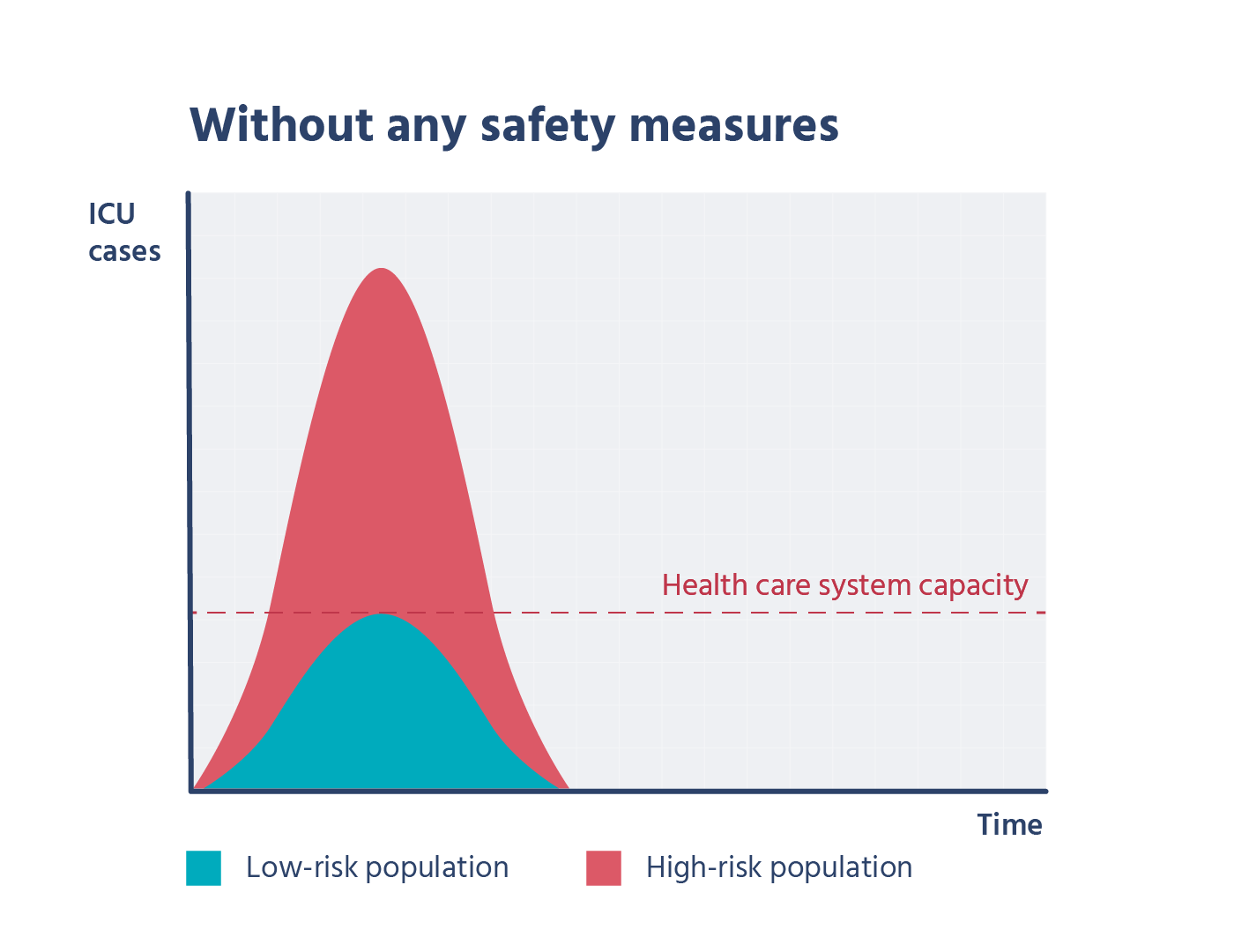
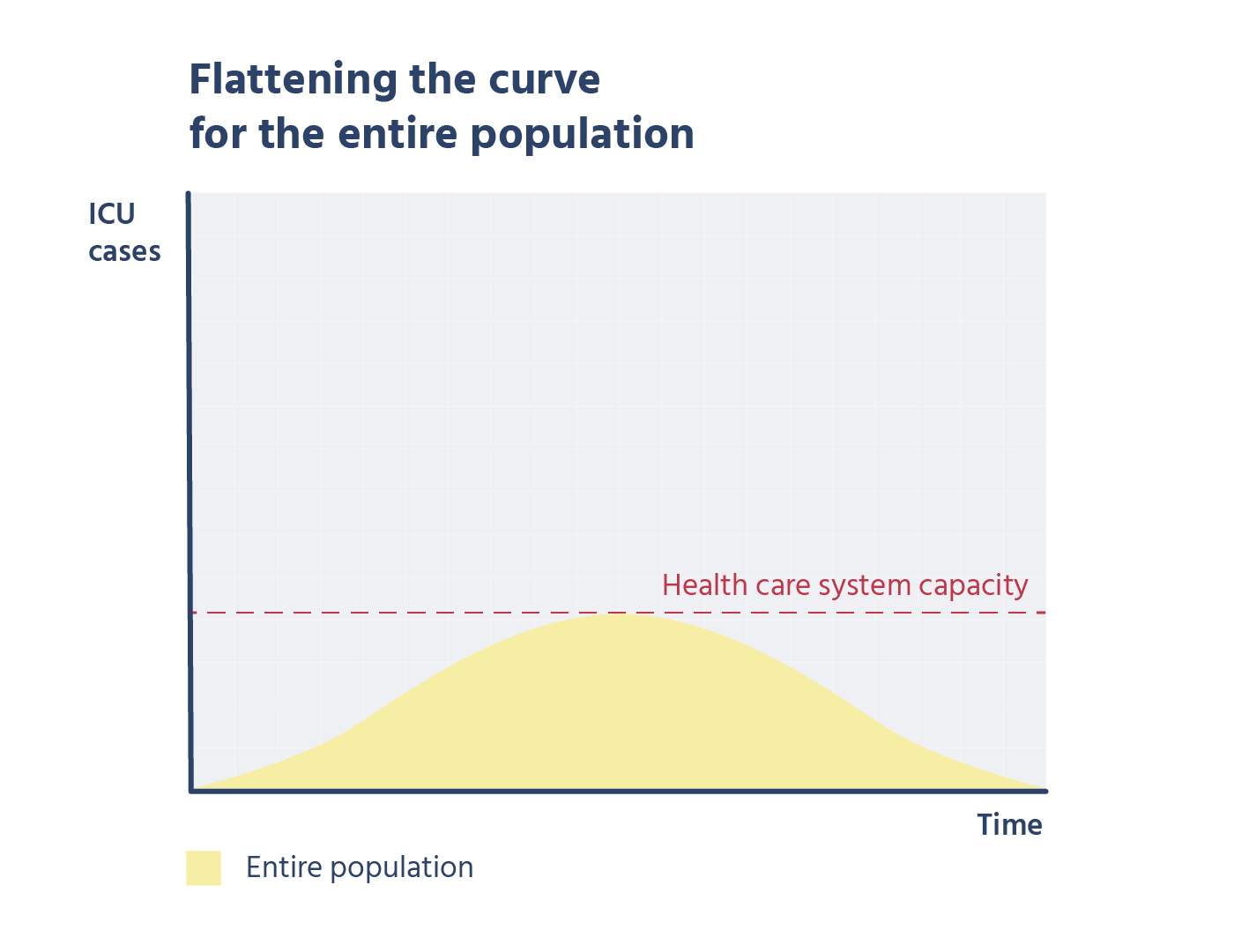
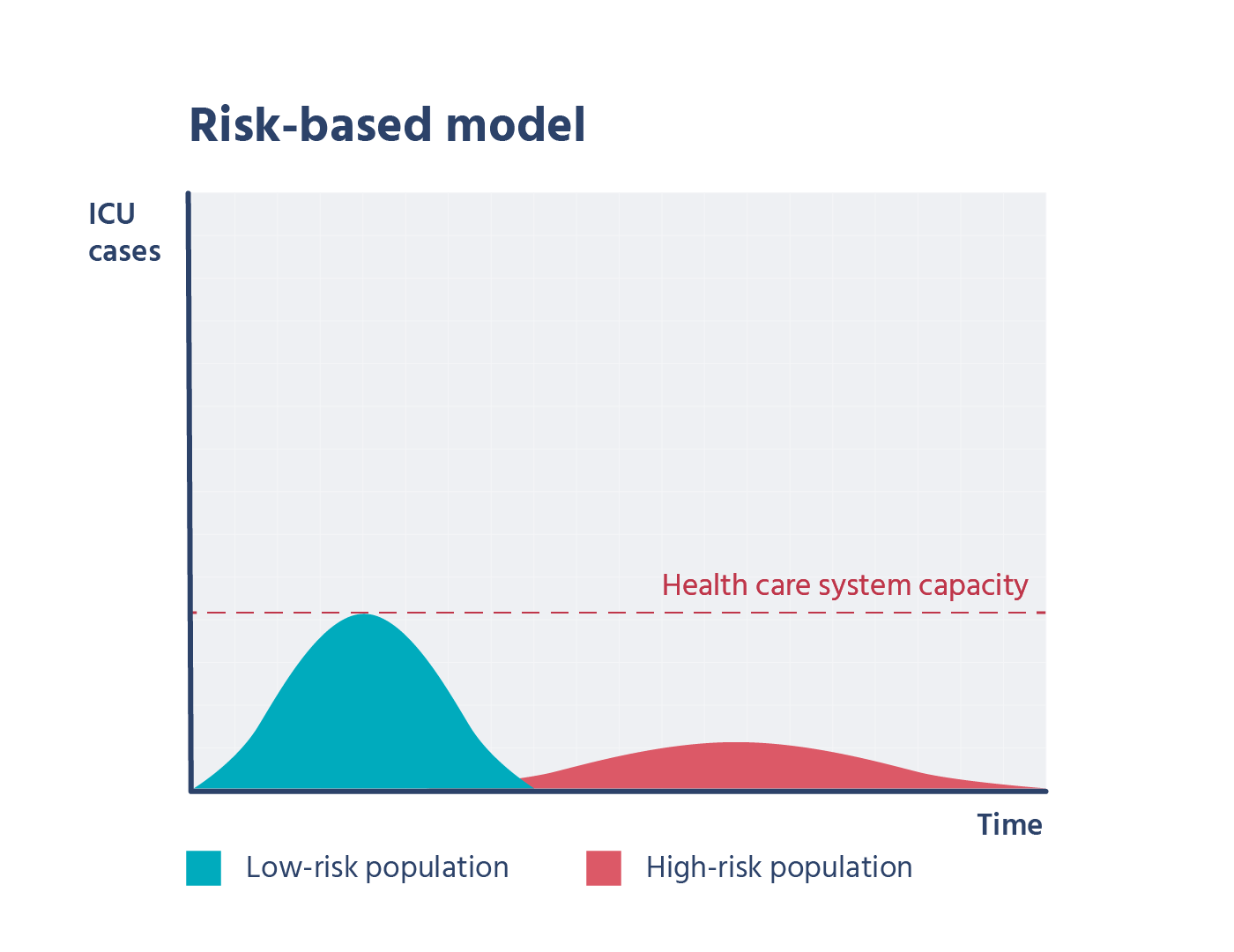
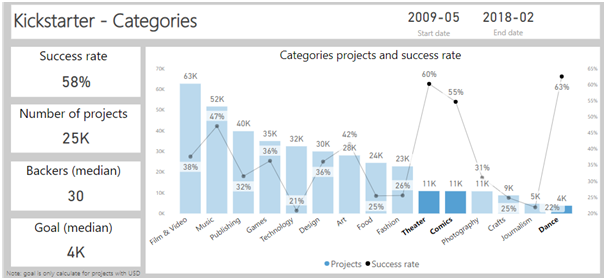
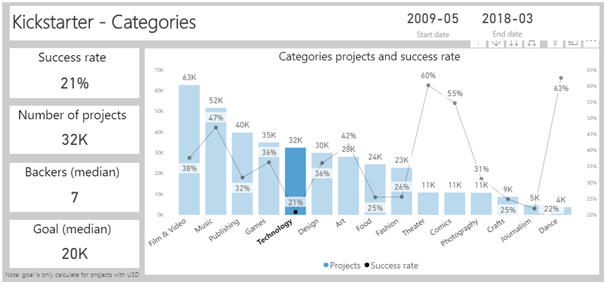
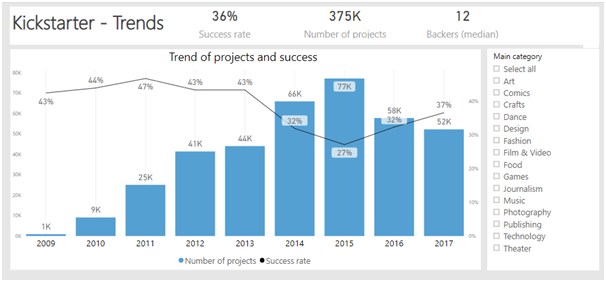
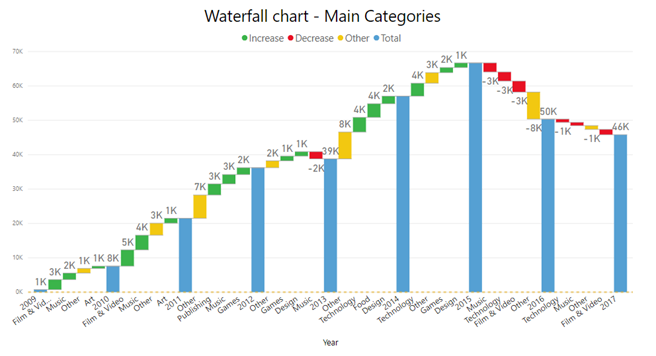
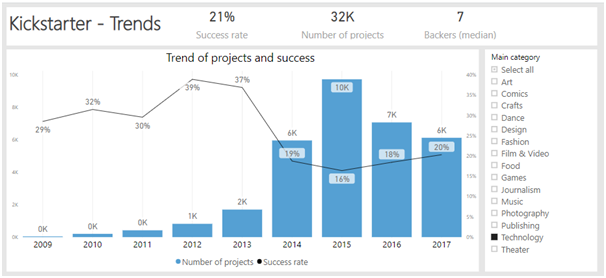
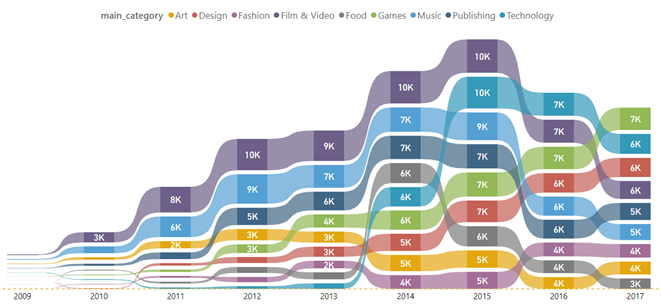
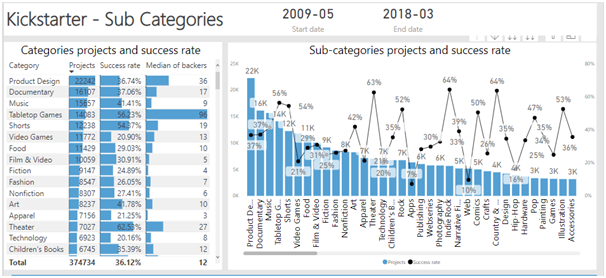
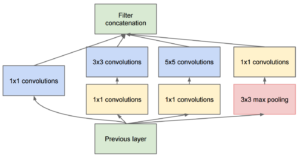
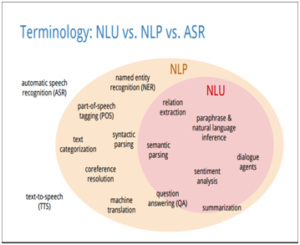
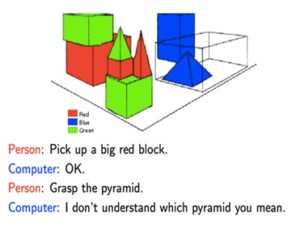
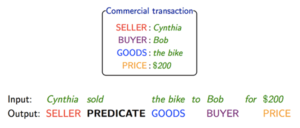
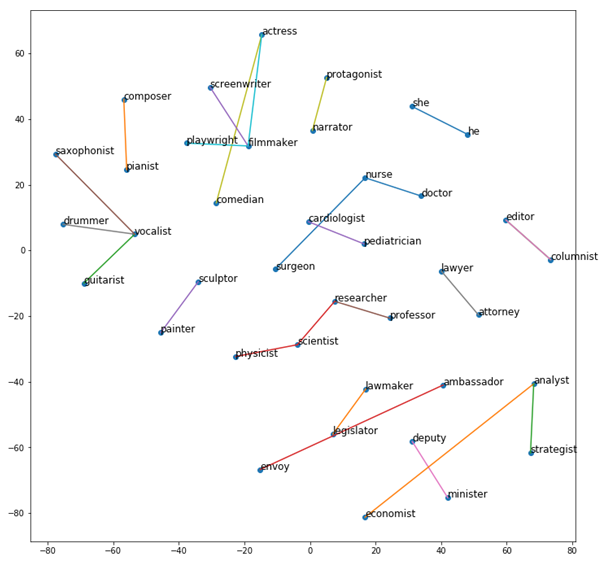
כשלמדתי לוגיקה בתואר ראשון, בכל המבחנים בכל מבחן הייתה שאלת הוכחה של משפט קנטור ברנשטיין או האלכסון של קנטור. בשנתון שלי הייתה ממש סצנה מהשאלה הזו, המרצה טעה בהוכחה בהרצאה, וההוכחה בסיכומים שכולם למדו מהם הייתה שגוייה. התלמידים שלמדו את ההוכחה כמו תוכי מהסיכום טעו, והמרצה לא הסכים לקבל את התשובה השגוייה, מסקנה- אם יש שאלה שבטוח תופיע, תלמדו אותה טוב טוב, והכי חשוב וודאו שאין לכם טעות בפתרון!
בראיונות עבודה זה בדיוק אותו דבר! בכל ראיון יבקשו ממכם לספר על פרויקט בעבודה הקודמת, פרוייקט צד, או על התזה.
מה מראיינים מנסים לבחון דרך הצגת הפרויקט?
- שיש לכם הבנה עמוקה של הדברים שנעשו, למה עשיתם X ולא Y.
- אתם יודעים להסביר דברים שעשיתם.
- אתם יודעים להסיק מסקנות לגבי מה עובד ומה לא.
- יש לכם יכולת לקרוא ולהבין מאמר.
- איך אתם מתמודדים עם בעיות.
- האם הקוד שלכם קריא, מסודר ומתועד.
- יכולת עבודה עם git.
- עשיית פרויקט יכול להצביע על אוטו-דידקטיות, זיקה לתחום ומוטיבציה.
- זה טבעי שלא תדעו הכל, פרויקט יכול לכוון את המרואיינים במה אתם מבינים ועל מה אפשר לשאול אתכם.
איך מתכוננים?

- כתבו תיאור מפורט של הפרויקט ומה עשיתם.
- vanishing gradient, עבר זמן ובטח יהיו פרטים ששכחתם. השלימו את הפרטים החסרים על ידי חזרה אל הקוד במידת האפשר. אם הקוד לא ברשותכם השלימו לפני ההיגיון. במה הייתם משתמשים אם הייתם צריכים לעשות את הפרוייקט היום.
- לטשו את הסיפור ופשטו את ההסברים. הסבירו את הסטינג של הבעייה, תארו את התהליך, מה הייתה המטרה, איך נגשתם לבעייה, מאיפה אספתם את הדאטה, מה הפתרונות הטריוויאלים שניסיתם בהתחלה ומדוע הם לא הספיקו או לא פתרו את הבעייה ? מה האתגרים בהם נתקלתם ? כיצד התמודדתם איתם? אחת הטעויות הנפוצות היא לחשוב שהמטרה היא להרשים ולכן מגיעים מהר מדי לפאנץ׳ – לפתרון המתוחכם שבניתם, התמקדו קודם להסביר את הקשיים והמטרה מדוע הפתרון שבחרת בו היה נחוץ.
- ספרו על הפרויקט לחברים שעובדים בתחום, תוודאו שהסיפור מוציא אותכם טוב. אם השתמשתם בשיטה לא יעילה, או הייתה לכם טעות, תתקנו.
- הסתכלו על דרישות המשרה שאתם מתראיינים אליה ונסו לחשוב אילו נקודות בסיפור שווה להדגיש כדי להראות שאתם עומדים בדרישות.
- טיפ למתקדמים: אנחנו רוצים ליחצן את היתרונות היחסיים שלנו, אבל לא רוצים להישמע שחצנים. במקום להגיד כל השיחה אני ואני ועשיתי ועשיתי ולדבר על עצמך יותר מידי באופן שיכול לגרום לנו להשמע שחצנים וקצת לא אמינים. בנוסף זה מחייב אותך גם לתת דוגמאות מדוע אני טוב בכל הדברים שאני אומר. אז מה פתרון הביניים?.אפשר לספר סיפור ולשזור בו נתונים על הרזומה והפעילויות שלנו, וכך המראיין יבין לבד. למשל “את הרעיון לפרויקט קיבלתי מהרצאה ששמעתי במיטאפ\כנס בחו”ל\ קורס מקוון שלקחתי\אהקטון שהשתתפתי בו\summer internship שעשיתי ב…, בתוכנית מצטיינים, קוד אופן סורס שאני תורם לו”. וכך אתם יכולים להעיד על עצמכם בעקיפין שאתם הולכים להרבה האקטונים, מיטאפים, תורמים לקוד פתוח, מצטיינים וכו’..
- ציירו שמש אסוציאציות וחשבו על כל השאלות שיכולים לשאול אתכם על הפרויקט למשל:
1. איזו בעייה ניסית לפתור?
2. באיזה דאטה השתמשת? איך היית מתמודד עם המשימה עם דאטא שונה ממה שהיה לך?
3. באיזה אלגוריתם\ארכיטקטורה השתמשת? למה דווקא בו? מה החסרונות והיתרונות שלו לעומת אחרים? איך הוא עובד?
4. באיזה בעיות נתקלת? איך פתרת אותן? מה היו הפתרונות האלטרנטיבים ומדוע בחרתם בפיתרון שלכם.
5. איך מדדת את הביצועים? מה היו היתרונות והחסרונות של שיטת המדידה?
6. וריאציות על הפרויקט, מה היה קורה אם במקום X היית עושה Y?
7. למה בחרת בגישה שבחרת?
8. מה היית עושה אם היינו מורידים אילוץ X ? או מוסיפים אילוץ Y?
9. מה הייתה עושה אם היה לה עוד כמה שבועות לעבוד על זה?
10. אם זה היה פרוייקט שכלל עבודת צוות תתכוננו גם לשאלות כמו: על איזה חלק הייתם אחראים? האם אתם יודעים איך החלקים האחרים עבדים? איך התנהלה חלוקת העבודה, מה עבד טוב ומה פחות?
שווה לנסות לשלב את התשובות לשאלות האלו בתוך הסיפור, כל עוד זה לא מסורבל מידי.
- כתבו תשובות להכל, תשננו תתאמנו מול מצלמה, מול המראה או מול חברים, ויש לכם שאלת מתנה בכיס.
ההכנות הנדרשות כדי לספר על פרויקט צד לוקחות זמן, ודורשות לחזור ולשחזר דברים שכבר שכחנו.
הזמן בו אנחנו יודעים לספר על הפרוייקט הכי טוב הוא ברגע שסיימנו לעבוד עליו, ולכן כאשר אתם מסיימים לעבוד על פרוייקט שווה לכתוב סיכום ואולי אפילו בלוג פוסט שמסביר לפרטי פרטים על מה עשיתם ועונה על השאלות שדיברנו אליהן.
פרויקטי צד כדרך חיים
אחד החסרונות בגישה שצריך לעשות פרוייקט צד גדול ומרשים היא שברוב המקרים או שבסוף לא עושים או לא מסיימים ואם כבר עושים ומסיימים אז זו ריצת מרתון חד פעמית שעושים כדי לסמן וי, ולא משתמשים בזה בתור כלי להתפתחות מקצועית לאורך זמן.
דיברתי עם חייל אקדמאי ביחידה טכנולוגית בצוות DS שמשתחרר בקרוב ועובד בזמנו החופשי על פרויקטי צד בצורה שוטפת.
במסגרת השירות שלו הוא הכשיר את עצמו בתחום של ויז’ן דיפ ולמידת מכונה, וכרגע הוא לומד את התחום הnlp- בעזרת קורס של FastAI.
איך אתה מגדיר פרוייקט אישי?
פרויקט בתחום ה ai, שבו אתה ממש מאמר/אלגוריתם בעצמך, על דאטה חדש, זה יכול להיות בכל מיני היבטים של הסתכלות על הדאטה ולהוציא תובנות חדשות או אפילו להבין בעצמך דברים שנראים טריוויאלים לאנשים אחרים
איך אתה בוחר על אילו פרויקטים לעבוד?
אם אני מוצא דברים מעניינים באינטרנט שאני רוצה לממש בעצמי או מרגיש שחסר לי יכולות בתחום מסוים, אז אני אקח את זה כפרויקט קטן ואשב על הנושא. נושאים נוספים יכולים לבוא כחלק מהצוות שעולה בעיה ואני אקח אותה על עצמי ובזמן הפנוי אני אכיר את הנושא ואלמד.
כשאתה עובד על פרויקט אתה חושב לעצמך האם הוא יהייה מרשים מספיק כדי להציג אותו בראיונות?
זה משתנה. רוב הדברים שאני עובד עליהם זה לא במטרה להרשים בראיון, אלה באמת במטרה ללמוד, להכיר מושג ולדעת לממש. לקחת את הרעיון ולהכניס אותו לדאטה שאנחנו עובדים עליו בצוות.
לדעתי, אם הייתי בצד של המראיין, מספיק שהמרואיין יכיר את התחום בגדול כדי שיוכל להצטרף במהירות לצוות.
לדעת לתכנת בלינוקס ולנהל גיט זה יתרון חשוב, אבל לא הייתי פוסל על זה.
עניין נוסף הוא שיכול להיות שעדיף שיהייה פרוייקט כמה שיותר גדול ורחב, הנוגע בהרבה נושאים להציג בראיון. אבל לרוב זה לא אפשרי לאנשים חדשים בתחום, לכן לדעתי עדיף לעשות מספר פרויקטים קטנים וזה יעשה את העבודה.
חלק מהדברים שאני עושה הם גם במטרה להרשים בראיונות, למשל הקורס NLP שאני עושה זה גם כדי לדעת, אבל גם כדי שיהיה לי תחום נוסף להגיד בראיון עבודה שאני מכיר.
אילו פרויקטים עצמאיים יצא לך לעשות בינתיים בתחום?
לקחתי קורס של דיפ באחת האוניברסיטאות, זה היה קורס של סוג של תחרות קאגל לפרדיקציה, ומשימה נוספת לעשות פרוייקט יצירתי. ממש אהבתי את הנושא כי הדאטה היה מעניין ומורכב.
היו מספר פרוייקטים בסיסים של ML מקאגל.
היו פרוייקטים של לממש מאמרים, לעשות דברים קלאסיים (ולא קלאסיים) בוויזין ולבצע השוואות (אם ניתן כתלות בפרוייקט).
פרוייקטי סיווג אודיו באמצעים קלאסיים ולא קלאסיים.
על מה אתה עובד עכשיו?
קורס NLP של fastai וקורס reinforcement learning של david silver.
רעיונות לפרויקטים

-
-
- לקחת את בעיית ה Object Detection ולאמן אותה על DB ייחודי כמו למשל זיהוי אמבות.
וריאציה נוספת אפשרית, אם למשל משתמשים ב YOLO לעשות anchors שאינם בהכרח מלבנים אלא צורות אחרות. (כוכבים, אליפסות…) - לקחת הקלטות (voice) של משפטים שכוללים את המילה “קורנה” וכאלו שלא, ולסווג. פה היכולת לעשות אוגמנטציה חכמה כנראה תהיה מאתגרת.
- לאמן רשת נוירונים שפותרת בעיה מתמטית. קל: מציאת צלע שלישית במשולש ישר זווית (מודל שמתאמן ללמוד את משפט פיתגרוס). קשה: פתרון למשוואה ממעלה 2,3,4,5… (מודל שמתאמן ללמוד את נוסחת השורשים)
- לאמן רשת נוירונים שמבצעת קלסיפיקציה על נתונים מקוריים. לדוגמא Google’s Quickdraw
דאטה סט של 50 מיליון ציורים מהירים מחולקים ל345 קטגוריות.
קוד נחמד בפייתון שהופך את הדאטה סט הזה לפורמט של MNIST ומחלק אותו לנתוני אימון ונתוני בדיקה. - קלסיפיקציה של מאגרי נתונים איזוטריים כמו רגשות, תמרורים…
- פרוייקט Ai שמשחק במשחק הדינוזאור של chrome:

בלוג פוסט שמסביר איך לעשות את זה - סיווג של תנוחות ידיים
לקבוע את מחוות היד בזמן אמת באמצעות מצלמת רשת. - לממש style transfer (יצירתיות אפשרית פה לא חסר…)
- סיווג ג’אנר מוזיקה
רשת שמזהה ג’אנרים של מוזיקה
מערך נתונים לסיווג ז‘אנר מוסיקה - פרויקט נחמד לחג הפסח: מד שבוחן האם אתם מסבים לשמאל כמו שצריך בעזרת pose estimation
https://github.com/Heladoo/HappyPassover
- לקחת את בעיית ה Object Detection ולאמן אותה על DB ייחודי כמו למשל זיהוי אמבות.
https://www.facebook.com/elad.amira/videos/10158577390038470
-
יש לכם עוד רעיונות, או פרויקטים שעשיתם ?
רישמו בהערות פה או בפייסבוק ונשמח להוסיף לכתבה כדי לתת לאחרים השראה!

 כלי SHAP עושה שימוש במתודולוגיה של תורת המשחקים כדי לחשב את התרומה של כל פיצ’ר לחיזוי הממוצע. הכלי מתאים לעצי החלטה אבל רגיש לסדר הפיצ’רים ואינו מאפשר סימולציות.
כלי SHAP עושה שימוש במתודולוגיה של תורת המשחקים כדי לחשב את התרומה של כל פיצ’ר לחיזוי הממוצע. הכלי מתאים לעצי החלטה אבל רגיש לסדר הפיצ’רים ואינו מאפשר סימולציות.